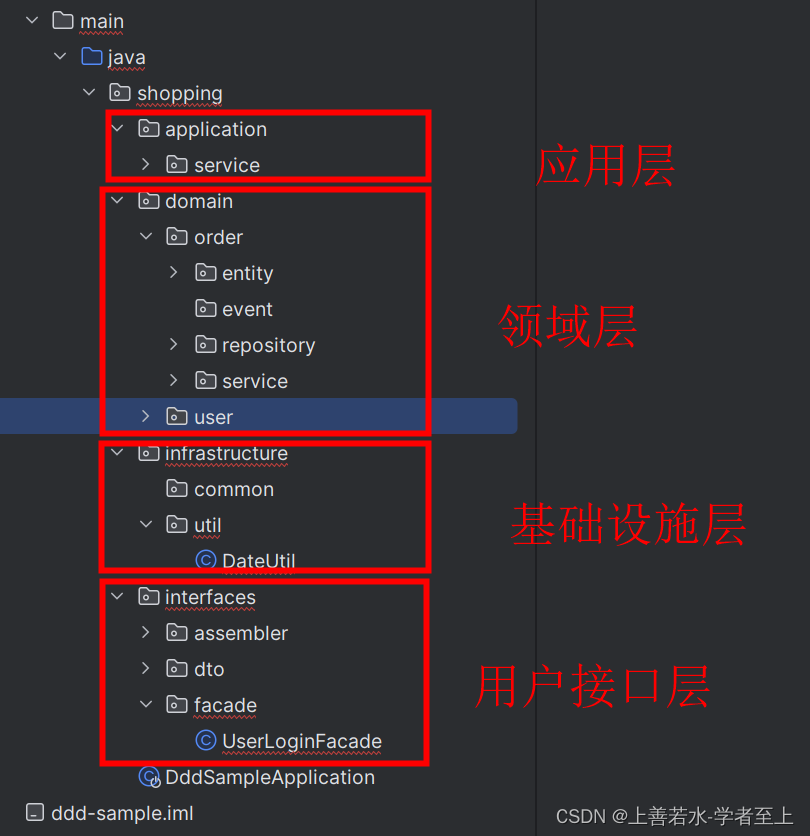
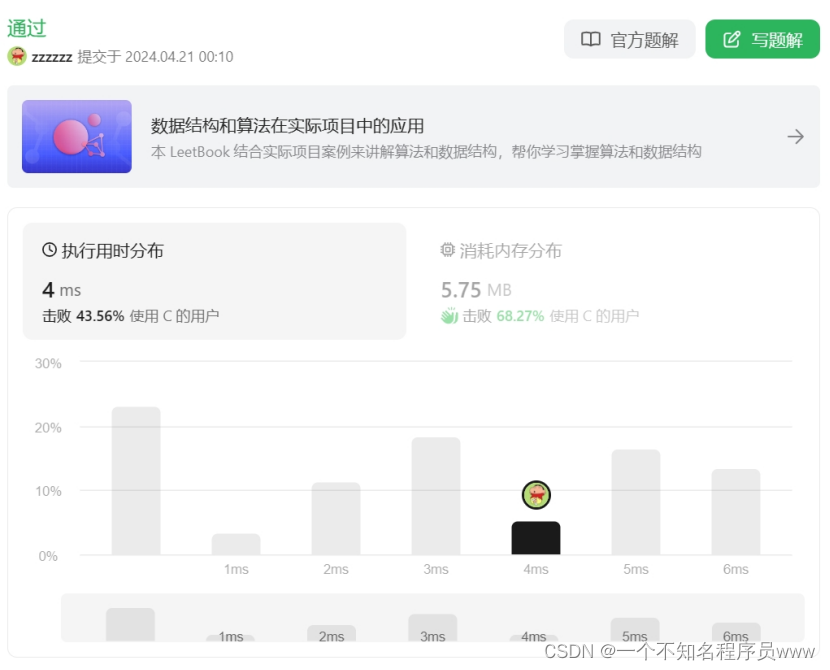
原文:
annas-archive.org/md5/655c944001312f47533514408a1a919a译者:飞龙
协议:CC BY-NC-SA 4.0
前言
序言
当你拿起这本书时,你可能会想,为什么又一本关于密码学的书?甚至,为什么我要读这本书?要回答这个问题,你必须了解它是什么时候开始的。
一本经过多年打磨的书
如今,如果你想学习几乎任何东西,你会谷歌它,或者必应它,或者百度它——你懂的。然而,对于密码学,取决于你要找的是什么,资源可能相当匮乏。这是我很久以前就遇到的问题,从那时起一直是持续的挫败感的来源。
在我还在学校时,我曾经为一门课程实现过差分功率分析攻击。那时,这种攻击是密码分析的一个突破,因为它是第一个公开发表的侧信道攻击。差分功率分析攻击是一种神奇的技术:通过在设备加密或解密时测量其功耗,你能够提取它的秘密。我意识到,优秀的论文可以传达出伟大的思想,而在清晰度和可理解性上却付出了很少的努力。我记得为了弄清作者想要表达的意思而一头撞在墙上。更糟糕的是,我找不到解释这篇论文的好的在线资源。所以我又撞了一会儿头,最终搞明白了。然后,我想,也许我可以帮助其他像我一样将要经历这一磨难的人。
受到鼓舞,我画了一些图表,加以动画处理,并录制了自己讲解它们的视频。那是我关于密码学的第一段 YouTube 视频:www.youtube.com/watch?v=gbqNCgVcXsM。
几年后,我上传了视频之后,我仍然从互联网上的陌生人那里收到赞扬。就在昨天,当我写这个序言时,有人发帖说:“谢谢你,真的是一个很好的解释,可能省了我好几个小时来理解那篇论文。”
这是多么大的一份奖励啊!在冒险探索教育领域的另一边迈出的这一小步足以让我想要做更多的事情。我开始录制更多这样的视频,然后我开始写一篇关于密码学的博客。你可以在这里查看:cryptologie.net。
在开始写这本书之前,我已经积累了将近 500 篇解释这个介绍之外许多概念的文章。这一切都只是练习。在我心里,写一本书的想法在 Manning Publications 与我联系提出书籍提案的几年前就在慢慢成熟。
现实世界的密码学课程
我完成了理论数学学士学位,不知道接下来该做什么。我一直在编程,而我想要协调这两者。自然而然地,我对密码学产生了兴趣,它似乎兼具了两者的优点,并开始阅读我能够得到的不同的书籍。我很快发现了自己的人生使命。
有些事情很让人烦恼,尤其是那些以历史开始的长篇介绍;我只对技术性感兴趣,一直以来都是如此。我发誓,如果我写一本关于密码学的书,我不会写一行有关维吉尼亚密码、凯撒密码和其他历史遗留物的内容。于是,在波尔多大学获得密码学硕士学位后,我以为我已经为现实世界做好了准备。我还是太天真了。
我相信我的学位足够了,但我的教育缺乏关于我即将攻击的真实世界协议的许多知识。我花了很多时间学习椭圆曲线的数学知识,但对这些在密码算法中如何使用却一无所知。我学习了有关 LFSR、ElGamal 和 DES 等一系列其他密码学原语,但我永远不会再见到它们。
在我开始在 Matasano(后来成为 NCC Group)工作时,我的第一个任务是审核 OpenSSL,这是最流行的 SSL/TLS 实现——这个代码基本上加密了整个互联网。哦,我的脑袋痛啊。我记得每天回家时头痛欲裂。这简直是一个灾难般的库和协议!当时我完全不知道,几年后我会成为 TLS 1.3 的合著者,这是该协议的最新版本。
但是,那时候,我已经在想,“这才是我应该在学校学到的东西。我现在获得的知识才是为了让我为真实世界做准备!”毕竟,我现在是一个专门从事密码学的安全从业者。我在审核真实世界的加密应用。我正在做人们在完成密码学学位后希望自己能做的工作。我实现了、验证了、使用了,并就应该使用哪些密码算法提供建议。这就是为什么我是我正在写的书的第一位读者。这就是我会写给过去的自己的东西,以便为他准备好面对现实世界。
大多数漏洞所在
我的咨询工作让我审核了许多真实世界的加密应用,如 OpenSSL、Google 的加密备份系统、Cloudflare 的 TLS 1.3 实现、Let’s Encrypt 的证书颁发协议、Zcash 加密货币的 sapling 协议、NuCypher 的门限代理重加密方案,以及其他许多真实世界的加密应用,可惜我不能在公开场合提及。
在我的职业生涯早期,我被指派审计一个知名公司编写的自定义协议以加密其通信。结果发现几乎所有内容都使用了签名,但暂时的密钥却没有,这完全破坏了整个协议,因为任何有一些安全传输协议经验的人都可以轻易地替换它们——这是一个新手的错误,但被认为有足够经验编写自己的加密协议的人却忽略了这一点。我记得在最后解释这个漏洞的时候,整个工程师室安静了好几十秒钟。
在我的职业生涯中,这个故事反复出现了很多次。有一次,当我为另一家客户审计加密货币时,我发现了一种方法可以伪造已经存在的交易,因为签名的内容有些模糊不清。在为另一家客户查看 TLS 实现时,我发现了一些微妙的方法来破坏 RSA 实现,结果,与 RSA 的一位发明者合作撰写了一篇白皮书,导致向十几个开源项目报告了许多公共漏洞和曝光(CVE)。最近,在写作我的书的过程中阅读了关于更新的 Matrix 聊天协议时,我意识到他们的身份验证协议存在问题,导致了他们端到端加密的破解。在使用密码学时,不幸的是,有很多细节可能会导致错误。在这一点上,我知道我必须写点东西来解决这些问题。这就是为什么我的书包含了这么多这样的轶事。
作为工作的一部分,我会审查多种编程语言中的密码学库和应用程序。我发现了一些漏洞(例如,Golang 标准库中的 CVE-2016-3959),研究了库如何欺骗您误用这些漏洞(例如,我的论文《如何植入迪菲-赫尔曼后门》),并就应该使用哪些库提供建议。开发人员从未知道该使用哪个库,而我总是发现答案很棘手。
我继续发明了 Disco 协议(discocrypto.com; embeddeddisco.com),并在不到 1000 行代码的情况下编写了其功能齐全的密码库,而且还涉及了多种语言。Disco 只依赖于两个密码学原语:SHA-3 的置换和 Curve25519。是的,仅凭这两个在 1000 行代码中实现的东西,开发人员就可以进行任何类型的身份验证密钥交换、签名、加密、MAC、哈希、密钥派生等等。这使我对一个好的密码库应该是什么有了独特的看法。
我想让我的书包含这些实用的见解。因此,不同的章节自然包含了如何在不同的编程语言中应用“密码学”的示例,使用备受尊敬的密码学库。
需要一本新书吗?
当我在著名的安全会议 Black Hat(黑帽大会)上举办我的年度密码学培训课程时,一名学生来找我,问我能否推荐一本好书或在线课程关于密码学。我记得建议学生阅读 Boneh 和 Shoup 的一本书,并参加 Coursera 上的 Boneh 的密码学 I 课程。(我也在本书的结尾推荐了这两个资源。)
学生告诉我,“啊,我尝试过,这太理论化了!” 这个回答一直留在我心里。起初我不同意,但慢慢意识到他们是对的。大多数资源在数学上非常深奥,而大多数与密码学交互的开发人员不想涉及数学。对他们来说还有什么选择呢?
当时另外两个颇受尊重的资源是(布鲁斯·施奈尔的两本书)。但这些书开始变得相当过时。应用密码学花了四章讨论分组密码,还有一整章讨论密码模式,但没有提及认证加密。更新一些的密码工程只在脚注中简单提到了椭圆曲线密码。另一方面,我的许多视频或博客文章正在成为一些密码概念的良好主要参考资料。我知道我可以做一些特别的事情。
渐渐地,我的许多学生开始对加密货币产生兴趣,对这个主题提出越来越多的问题。与此同时,我开始审计越来越多的加密货币应用程序。后来,我转到 Facebook 工作,负责领导 Libra 加密货币(现在称为 Diem)的安全工作。当时,加密货币是最热门的领域之一,混合了许多极其有趣的密码原语,迄今为止几乎没有在现实世界中使用过(零知识证明、聚合签名、门限密码学、多方计算、共识协议、密码累加器、可验证随机函数、可验证延迟函数等等……清单还在继续)。然而,没有一本密码学书籍包含了关于加密货币的章节。我现在处于一个独特的位置。
我知道我可以写一本书,告诉学生、开发人员、顾问、安全工程师以及其他人现代应用密码学究竟是什么。这将是一本几乎没有公式但充满许多图表的书。这将是一本几乎没有历史但充满我亲眼目睹的现代密码失败故事的书。这将是一本几乎没有关于传统算法的书,但充满我个人见过的大规模使用的密码学:TLS、Noise 协议框架、Signal 协议、加密货币、HSM、门限密码学等等。这将是一本几乎没有理论密码学但充满可能变得相关的内容:密码认证密钥交换、零知识证明、后量子密码学等等。
当 Manning 出版社在 2018 年联系我,问我是否想要写一本关于密码学的书时,我已经知道了答案。我已经知道我想写什么了。我只是在等待着有人给我机会和借口来花时间写我心中的那本书。巧合的是,Manning 有一系列“真实世界”的书籍,所以自然而然地,我建议我的书扩展它。你眼前的是两年多的辛勤工作和大量热爱的成果。我希望你喜欢。
致谢
感谢 Marina Michaels 一直以来的帮助和见解,如果没有她,这本书可能不会完成。
感谢 Frances Buran,Sam Zaydel,Michael Rosenberg,Pascal Knecht,Seth David Schoen,Eyal Ronen,Saralynn Chick,Robert Seacord,Eloi Manuel,Rob Wood,Hunter Monk,Jean-Christophe Forest,Liviu Bartha,Mattia Reggiani,Olivier Guerra,Andrey Labunov,Carl Littke,Yan Ivnitskiy,Keller Fuchs,Roman Zabicki,M K Saravanan,Sarah Zennou,Daniel Bourdrez,Jason Noll,Ilias Cherkaoui,Felipe De Lima,Raul Siles,Matteo Bocchi,John Woods,Kostas Chalkias,Yolan Romailler,Gerardo Di Giacomo,Gregory Nazario,Rob Stubbs,Ján Jancˇár,Gabe Pike,Kiran Tummala,Stephen Singam,Jeremy O’Donoghue,Jeremy Boone,Thomas Duboucher,Charles Guillemet,Ryan Sleevi,Lionel Rivière,Benjamin Larsen,Gabriel Giono,Daan Sprenkels,Andreas Krogen,Vadim Lyubashevsky,Samuel Neves,Steven(Dongze)Yue,Tony Patti,Graham Steel,以及所有 livebook 评论者的许多讨论和纠正,以及技术和编辑反馈。
感谢所有审阅者:Adhir Ramjiawan,Al Pezewski,Al Rahimi,Alessandro Campeis,Bobby Lin,Chad Davis,David T Kerns,Domingo Salazar,Eddy Vluggen,Gábor László Hajba,Geert Van Laethem,Grzegorz Bernas´,Harald Kuhn,Hugo Durana,Jan Pieter Herweijer,Jeff Smith,Jim Karabatsos,Joel Kotarski,John Paraskevopoulos,Matt Van Winkle,Michal Rutka,Paul Grebenc,Richard Lebel,Ruslan Shevchenko,Sanjeev Jaiswal,Shawn P Bolan,Thomas Doylend,William Rudenmalm,感谢您的建议,这使得这本书更加完善。
关于本书
现在距我开始写《真实世界密码学》已经过去两年多了。我最初打算让它成为一本介绍实际世界中使用的密码学的所有内容的入门书。但是,当然,这是一个不可能的任务。没有一个领域可以用一本书来总结。因此,我不得不在我想给读者的详细程度和我想覆盖的领域之间取得平衡。我希望你发现自己和我一样陷入了同样的困境。如果你正在寻找一本实用的书,教你企业和产品实现和使用的密码学,以及如果你对实际世界的密码学是如何在表面下工作感兴趣,但不是在寻找一个包含所有实现细节的参考书,那么这本书适合你。
谁应该读这本书
这是我认为会受益于这本书的人群类型的列表(尽管请不要让任何人将你归类为某种类型)。
学生
如果你正在学习计算机科学、安全或密码学,并希望了解现实世界中的密码学(因为你要么在瞄准行业工作,要么想在学术界从事应用主题),那么我认为这本教材适合你。为什么呢?因为,正如我在前言中所说的,我曾经也是这样的学生,我写了我那时希望有的那本书。
安全从业者
渗透测试人员,安全顾问,安全工程师,安全架构师以及其他安全角色组成了我教应用密码学时大多数学生的人群。因此,这些材料是通过我在试图向非密码学家解释复杂的密码学概念时收到的许多问题加以完善的。作为一个安全从业者,这本书也受到了我为大公司审计的密码学以及我在途中学到或发现的错误的影响。
直接或间接使用密码学的开发人员
这项工作也受到了我与客户和同事之间的许多讨论的影响,这些人大多既不是安全从业者也不是密码学家。如今,编写代码而不涉及密码学越来越困难,因此,你需要对你所使用的东西有一定的了解。这本书通过不同编程语言的编码示例以及其他更多内容来给你这种理解,如果你感兴趣的话。
密码学家对其他领域感兴趣
这本书是应用密码学的介绍,对像我这样的人很有用。首先我是为自己写的,记住这一点。如果我做得不错,一个理论密码学家应该能够快速理解应用密码学世界的样貌;另一个在对称加密上工作的人应该能够通过阅读相关章节迅速掌握密码验证密钥交换;一个与协议工作的人应该能够迅速地了解量子密码学;依此类推。
工程和产品经理想要了解更多的人
这本书还试图回答我认为更注重产品的问题:这些方法的权衡和限制是什么?我面临什么风险?这条路会帮我遵守法规吗?我需要这样做那样做才能与政府合作吗?
好奇的人想要了解现实世界的加密
你不需要是我之前列出的任何一种类型才能读这本书。你只需要对现实世界中的密码学感兴趣。请记住,我不教授密码学的历史,也不教授计算机科学的基础知识,所以至少,在阅读这样一本书之前,你应该听说过密码学。
假定的知识,长版本
为了最大限度地利用这本书,你需要什么?你应该知道这本书假设你对你的笔记本电脑或互联网的工作方式有一些基本的了解,至少,你应该听说过加密。这本书是关于真实世界的密码学,所以如果你不熟悉计算机或者以前从未听说过encryption这个词,那么很难将事情放在上下文中。
假设你在某种程度上知道你在做什么,如果你知道比特和字节是什么,如果你看过甚至使用过像异或、左移这样的位运算,那就是一个真正的优势。如果你没有?不,但这可能意味着你需要不时停下来花几分钟在读书之前进行一些谷歌搜索。
实际上,无论你有多么有资格,当阅读这本书时,你可能会不时停下来,以获取更多来自互联网的信息。要么是因为我(真是可耻)在使用术语之前忘记了定义它,要么是因为我错误地认为你会了解它。无论如何,这应该不是什么大事,因为我尽力以最简单的方式解释我介绍的不同概念。
最后,当我使用cryptography这个词时,你的大脑可能会想到数学。如果除了那个想法,你的脸还皱起了,那么你会很高兴地知道你不必太担心。真实世界的密码学是关于教授见解,以便你对所有这些是如何运作有直观的理解,并且尽可能避免数学细节。
当然,如果我说制作这本书没有涉及数学,那就是在撒谎了。没有数学就没有教授密码学。所以我要说的是:如果你在数学方面取得了良好的水平,那会有所帮助,但如果没有,这不应该阻止你阅读这本书的大部分内容。除非你对数学有更高级的理解,否则一些章节对你来说可能不友好,特别是最后两章(第十四章和第十五章)关于量子密码学和下一代密码学,但没有什么是不可能的,你可以通过意志力和谷歌搜索矩阵乘法和其他你可能不了解的事物来应对这些章节。如果你决定跳过这些章节,请确保你不要跳过第十六章,因为那是锦上添花。
这本书的组织方式:一份路线图
真实世界的密码学分为两部分。第一部分应该从第一页读到最后一页,涵盖了大部分密码学的成分:像乐高一样的东西,用来构建更复杂的系统和协议。
-
第一章是关于真实世界密码学的介绍,给你一些你将学到的内容的概念。
-
第二章讨论了哈希函数,这是密码学中使用的一种基本算法,用于从字节串创建唯一标识符。
-
第三章讲述了数据认证以及你如何确保没有人修改你的消息。
-
第四章讲述了加密,它允许两个参与者将他们的通信隐藏起来,使观察者无法看到。
-
第五章介绍了密钥交换,它允许你与他人进行交互地协商一个共同的秘密。
-
第六章描述了非对称加密,它允许多人将消息加密给单个人。
-
第七章讨论了签名,密码学等效于笔和纸签名。
-
第八章讲述了随机性以及如何管理你的秘密。
本书的第二部分包含了由这些成分构建的系统。
-
第九章教你如何使用加密和认证来保护机器之间的连接(通过 SSL/TLS 协议)。
-
第十章描述了端对端加密,这实际上是关于像你和我这样的人如何相互信任的。
-
第十一章展示了机器如何认证人,并且人们如何帮助机器相互同步。
-
第十二章介绍了新兴的加密货币领域。
-
第十三章重点介绍了硬件密码学,这些设备可以用来防止你的密钥被提取。
有两个附加章节:第十四章介绍了后量子密码学,第十五章介绍了下一代密码学。这两个领域开始进入产品和公司,要么是因为它们变得更加相关,要么是因为它们变得更加实用和高效。虽然如果你跳过这最后两章我不会责怪你,但你必须在把这本书放回书架之前仔细阅读第十六章(结语)。第十六章总结了密码学从业者(也就是你,一旦你完成这本书)必须牢记的不同挑战和不同教训。就像蜘蛛侠的本·帕克叔叔说的:“伴随着伟大的力量而来的是伟大的责任。”
关于代码
本书包含许多源代码示例,既在编号列表中,也在普通文本中。在这两种情况下,源代码都以fixed-width font like this的格式进行排版,以区分它与普通文本。有时,代码也会以**in bold**的形式呈现,以突出显示从章节中的先前步骤中改变的代码,例如当新功能添加到现有代码行时。
在许多情况下,原始源代码已经重新格式化;我们添加了换行符和重新调整了缩进,以适应书中可用的页面空间。在罕见情况下,甚至这都不够,列表包括行连续标记(➥)。此外,在文本中描述代码时,源代码中的注释通常已被从列表中删除。代码注释伴随着许多列表,突出显示重要概念。
liveBook 讨论论坛
购买包括免费访问由 Manning Publications 运行的私人网络论坛,您可以在那里对这本书发表评论,提出技术问题,并从作者和其他用户那里获得帮助。要访问论坛,请转到livebook.manning.com/book/real-world-cryptography/discussion。您还可以在livebook.manning.com/discussion了解有关 Manning 论坛和行为规则的更多信息。
Manning 对我们的读者的承诺是提供一个场所,让个别读者之间以及读者与作者之间进行有意义的对话。这不是对作者参与的任何特定数量的承诺,作者对论坛的贡献仍然是自愿的(且未付费的)。我们建议您尝试向作者提出一些具有挑战性的问题,以免他失去兴趣!只要这本书还在印刷中,您可以从出版商的网站访问论坛和以前的讨论档案。
关于作者
David Wong是 O(1) Labs 的高级密码学工程师,负责 Mina 加密货币。在此之前,他是 Facebook 的 Diem(原名 Libra)加密货币的安全主管,之前是 NCC Group 的密码服务实践的安全顾问。David 还是《现实世界的密码学》一书的作者。
在他的职业生涯中,David 参与了几个公开资助的开源审计项目,如 OpenSSL 和 Let’s Encrypt。他曾在各种会议上发表演讲,包括黑帽大会和 DEF CON,并在黑帽大会上教授了一门关于密码学的课程。他为 TLS 1.3 和 Noise 协议框架做出了贡献。他发现了许多系统中的漏洞,包括 Golang 标准库中的 CVE-2016-3959,以及各种 TLS 库中的 CVE-2018-12404、CVE-2018-19608、CVE-2018-16868、CVE-2018-16869 和 CVE-2018-16870。
他是 Disco 协议(www.discocrypto.com和www.embeddeddisco.com)和智能合约的去中心化应用安全项目(www.dasp.co)的作者之一。他的研究包括对 RSA 的缓存攻击(cat.eyalro.net/)、基于 QUIC 的协议(eprint.iacr.org/2019/028)、对 ECDSA 的时序攻击(eprint.iacr.org/2015/839)或者 Diffie-Hellman 中的后门(eprint.iacr.org/2016/644)。您可以在他的博客www.cryptologie.net上看到并阅读有关他的信息。
关于封面插图
《现实世界的加密学》 封面上的图画标题为“Indienne de quito”,即基多印第安人。这幅插图取自雅克·格拉塞·德·圣索维尔(Jacques Grasset de Saint-Sauveur,1757–1810)收集的各国服装装束,题为 《不同国家的服装》 ,于 1797 年在法国出版。每幅插图都是精细绘制并手工着色的。格拉塞·德·圣索维尔的收藏丰富多样,生动地提醒我们,仅 200 年前,世界各地的城镇和地区在文化上是多么的不同。人们相互隔离,说着不同的方言和语言。在街道上或乡间,仅凭着他们的服装就能轻易地辨认出他们的居住地和他们的职业或社会地位。
自那时以来,我们的穿着方式已经发生了变化,地区间的多样性,当时如此丰富,已经消失了。如今很难区分不同大陆的居民,更不用说不同的城镇、地区或国家了。也许我们已经用更多样化的个人生活,甚至是更多样化和快节奏的技术生活来交换了文化多样性。
在如今难以区分一本计算机书籍与另一本之际,曼宁(Manning)通过基于格拉塞·德·圣索维尔的图片再现两个世纪前丰富多样的地区生活,来庆祝计算机行业的创造力和主动性。
第一部分:原语:密码学的基本组成部分
欢迎来到密码学的现实世界!你手中的这本书(如果你选择获取印刷版本)分为两个相等的部分,共有八章。通过阅读整本书,你将了解几乎所有关于现实世界密码学的知识——就是你所处的这个世界。
请注意,本书的第一部分是按顺序阅读的,尽管每一章都会告诉你前提条件是什么,所以不要把这看作是一种强制性的限制。前八章带你了解基础知识——密码学的基本构建块。每一章介绍一个新的原语,并教你它的作用、工作原理以及它如何与其他元素结合使用。本书的第一部分旨在在我们开始利用全部内容之前,为你提供良好的抽象和见解。
祝你好运!
第一章:引言
本章涵盖
-
密码学的内涵
-
理论与现实中的密码学
-
你将在这次冒险中学到什么
问候,旅行者;坐稳了。你即将进入一个充满奇迹和神秘的世界——密码学的世界。密码学是一门古老的学科,旨在保护受到恶意人物侵扰的情况。这本书包括了我们需要防御自己免受恶意的咒语。许多人尝试学习这门技艺,但很少有人能在掌握之前生存下来,因为掌握这门技艺面临着重重挑战。的确,令人兴奋的冒险在等待着!
在这本书中,我们将揭示密码算法如何保护我们的信件,识别我们的盟友,并保护我们的宝藏免受敌人的侵害。穿越密码学的海洋将不会是一次最顺利的旅程,因为密码学是我们世界安全和隐私的基础——最轻微的错误都可能致命。
注意 如果你发现自己迷失了方向,请记得继续向前走。一切最终都会变得清晰起来。

1.1 密码学是关于保护协议的
我们的旅程从介绍密码学开始,这是一门旨在防御协议免受破坏者侵害的科学。但首先,什么是协议?简单来说,它是一个(或多个人)必须遵循一系列步骤以实现某事的步骤列表。例如,想象一下以下假设:你想将你的魔剑无人看管几个小时,这样你就可以小睡一会儿。一个做到这一点的协议可能是这样的:
-
将武器放在地上
-
在树下小睡一会儿
-
从地上取回武器
当然,这并不是一个很好的协议,因为任何人都可以在你小睡时偷走你的剑……因此,密码学是考虑到那些想要利用你的对手的。
在古代,当统治者和将军们忙于背叛彼此和策划政变时,他们最大的问题之一就是如何与他们信任的人分享机密信息。从这里,密码学的概念诞生了。经过几个世纪的努力和辛勤工作,密码学才成为今天严肃的学科。现在,它在我们周围被广泛使用,以在我们混乱和不利的世界中提供最基本的服务。
这本书的故事是关于密码学的实践。它带领你在整个计算机世界中进行探险,介绍了当今正在使用的密码协议;它还向你展示了它们由什么部分组成以及如何组合在一起。虽然一本典型的密码学书通常是从密码学的发现开始,然后带你穿越它的历史,但我认为用这种方式开始事情没有太多意义。我想告诉你实用的东西。我想告诉你我亲眼所见的,作为一家大公司的顾问审查密码应用,或者作为领域工程师自己使用的密码学。
几乎不会有可怕的数学公式。本书的目的是揭示密码学的神秘,调查当今被认为有用的内容,并提供关于你周围事物是如何构建的直觉。本书面向对此感兴趣的人,有冒险精神的工程师,冒险的开发者和好奇的研究人员。第一章,本章,开始了对密码学世界的探索之旅。我们将发现不同类型的密码学,哪些对我们重要,以及世界是如何同意使用这些的。
1.2 对称加密:什么是对称加密?
密码学的一个基本概念是对称加密。它在本书中的大多数密码算法中使用,因此非常重要。我通过我们的第一个协议在这里介绍这个新概念。
让我们想象一下,女王爱丽丝需要给住在几个城堡之外的鲍勃勋爵发送一封信。她请求她忠诚的信使骑着他可靠的坐骑,冒着前方危险的土地,为了将珍贵的消息送到鲍勃勋爵手中。然而,她心存疑虑;即使她的忠诚信使为她服务多年,她希望在传输过程中的消息对所有被动观察者保密,包括信使!你看,这封信很可能包含了一些关于途中王国的有争议的八卦。

女王爱丽丝需要的是一个模拟将消息直接交给鲍勃勋爵而没有中间人的协议。这在实践中是一个几乎不可能解决的问题,除非我们引入密码学(或者传送)到方程中。这就是我们很久以前通过发明一种新类型的加密算法——称为对称加密算法(也称为密码)来解决的问题。
顺便说一下,一种加密算法通常被称为原语。你可以把原语看作是密码学中最小的、有用的构造,通常与其他原语一起使用以构建协议。这主要是一个术语,没有特别重要的意义,尽管它在文献中经常出现,但了解它是很好的。
让我们看看如何使用加密原语来隐藏女王爱丽丝的消息免受信使的干扰。现在想象一下,这个原语是一个黑匣子(我们看不到里面或者它内部在做什么),提供两个函数:
-
ENCRYPT
-
DECRYPT
第一个函数,ENCRYPT,通过取一个秘钥(通常是一个大数)和一个消息来工作。然后输出一系列看起来像随机数的数字,一些嘈杂的数据。我们将称这个输出为加密消息。我在图 1.1 中说明了这一点。

图 1.1 ENCRYPT 函数接受一个消息和一个秘钥,并输出加密消息——一长串看起来像随机噪音的数字。
第二个函数 DECRYPT 是第一个函数的反函数。它使用相同的秘钥和第一个函数的随机输出(加密的消息),然后找到原始消息。我在图 1.2 中进行了说明。

图 1.2 DECRYPT 函数接收一个加密的消息和一个秘钥,并返回原始消息。
要使用这个新的原语,女王艾丽斯和鲍勃勋爵必须首先在现实生活中见面并决定使用什么秘钥。稍后,女王艾丽斯可以使用提供的 ENCRYPT 函数,借助秘钥保护消息。然后,她将加密的消息传递给她的信使,最终将其传递给鲍勃勋爵。然后,鲍勃勋爵使用相同的秘钥对加密的消息使用 DECRYPT 函数来恢复原始消息。图 1.3 显示了这个过程。

图 1.3(1)艾丽斯使用带有秘钥的 ENCRYPT 函数将她的消息转换为噪音。(2)然后她将加密的消息传递给她的信使,后者不会了解到底层消息的任何信息。(3)一旦鲍勃收到加密的消息,他可以使用与艾丽斯相同的秘钥使用 DECRYPT 函数来恢复原始内容。
在这个交换过程中,信使所拥有的只是看起来随机的东西,它对隐藏消息的内容没有任何有意义的见解。实际上,借助密码学的帮助,我们将我们的不安全协议增强为安全协议。新的协议使女王艾丽斯能够向鲍勃勋爵发送一封机密信件,而没有任何人(除了鲍勃勋爵)了解其内容。
使用秘钥将事物渲染成噪音,使其与随机无法区分的过程,在密码学中是一种常见的安全协议保护方式。随着你在接下来的章节中学习更多密码算法,你会看到更多这样的内容。
顺便说一句,对称加密是密码学算法的一个更大类别的一部分,称为对称密码学或秘密密钥密码学。这是由于密码原语暴露的不同函数使用相同的密钥。后面你会看到,有时会有不止一个密钥。
1.3 克尔克霍夫原则:只有密钥是保密的
设计一个密码算法(就像我们的加密原语)是一件容易的事情,但设计一个安全的密码算法并不是胆小之人能够做到的。虽然我们在这本书中避免创建这样的算法,但我们确实学会了如何识别优秀的算法。这可能会很困难,因为选择太多,超出了任务所需。在密码学的历史中反复失败的经验教训以及社区从中学到的教训中可以找到一些提示。当我们回顾过去时,我们将领会到什么将密码算法变成一个值得信赖的安全算法。
数百年过去了,许多皇后和领主被埋葬了。从那时起,纸张被放弃作为我们主要的交流方式,转而采用更好更实用的技术。如今,我们可以接触到强大的计算机以及互联网。更实用,当然,但这也意味着我们之前的恶意传送者变得更加强大。他现在无处不在:你所在的星巴克咖啡厅的 Wi-Fi、构成互联网并转发你的消息的不同服务器,甚至在运行我们算法的机器上。我们的敌人现在能够观察到更多的消息,因为你向网站发出的每个请求都可能通过错误的线路,并在几纳秒内被改变或复制,而没有人注意到。
在我们之前,我们可以看到最近的历史中有许多加密算法失效的例子,被秘密国家组织或独立研究人员破解,并未能保护其消息或实现其声明。我们吸取了许多教训,并逐渐了解了如何制造良好的密码学。
注意,密码算法可以通过多种方式被视为破解。对于加密算法,你可以想象到多种攻击算法的方法:秘密密钥可以泄露给攻击者,消息可以在没有密钥的情况下解密,仅通过查看加密消息就可以透露一些关于消息的信息,等等。任何会削弱我们对算法做出的假设的事情都可以被视为破解。
密码学经历了漫长的试验和错误过程后,产生了一个强有力的概念:要对密码原语所声称的安全性进行信任,就必须由专家公开分析该原语。否则,你就是在依赖安全性通过模糊性,这在历史上并不奏效。这就是为什么密码学家(构建者)通常会寻求密码分析家(破解者)的帮助来分析一个构造的安全性。(尽管密码学家经常自己也是密码分析家,反之亦然。)

让我们以高级加密标准(AES)加密算法为例。AES 是由美国国家标准与技术研究院(NIST)组织的国际竞赛的产物。
注意,NIST 是一个美国机构,其角色是定义政府相关职能以及其他公共或私营组织使用的标准并制定指南。像 AES 一样,它标准化了许多广泛使用的密码原语。
AES 竞赛持续了数年,期间来自世界各地的许多志愿密码分析师聚集在一起,试图打破各种候选结构。几年后,通过这个过程建立了足够的信心后,一个单一的竞争性加密算法被提名为成为高级加密标准本身。现在,大多数人相信 AES 是一种可靠的加密算法,并且被广泛用于几乎所有的加密。例如,当你浏览网页时,你每天都在使用它。
在公开建立加密标准的想法与一个经常被称为Kerckhoffs’ principle的概念有关,可以理解为这样一种情况:依赖于我们的敌人不会发现我们使用的算法是愚蠢的,因为他们很可能会发现。相反,让我们对此持开放态度。
如果女王艾丽斯和鲍勃勋爵的敌人确切地知道他们是如何加密消息的,那么他们的加密算法如何安全?答案是秘钥!秘钥的保密性使得协议安全,而不是算法本身的保密性。这是本书的一个常见主题:我们将要学习的所有加密算法,以及实际世界中使用的加密算法,大多数情况下是可以自由学习和使用的。只有作为这些算法输入的秘钥是保密的。1644 年,让·罗伯特·迪·卡莱特(Jean Robert du Carlet)说:“Ars ipsi secreta magistro”(即使对于大师来说也是秘密的艺术)。在接下来的部分中,我将谈论一种完全不同类型的密码原语。现在,让我们使用图 1.4 来整理我们迄今为止学到的知识。

图 1.4 到目前为止你学到的密码算法。AES 是对称加密算法的一个实例,它是更广泛的对称加密算法类别的一部分。
1.4 非对称加密:两把钥匙比一把好
在我们关于对称加密的讨论中,我们说女王艾丽斯和鲍勃勋爵首先见面商定一个对称秘钥。这是一个合理的情景,实际上很多协议确实是这样工作的。然而,在有许多参与者的协议中,这很快就变得不太实际:我们需要我们的网络浏览器与谷歌、Facebook、亚马逊以及其他数十亿个网站见面,然后才能安全地连接到它们吗?
这个问题,通常称为密钥分配,在很长一段时间内一直很难解决,至少直到 20 世纪 70 年代末另一类大而有用的密码算法被发现,称为非对称密码学或公钥密码学。非对称密码学通常使用不同的密钥来执行不同的功能(与对称密码学中使用的单个密钥相对),或者为不同的参与者提供不同的观点。为了说明这意味着什么以及公钥密码学如何帮助建立人与人之间的信任,我将在本节中介绍一些非对称原语。请注意,这只是你将在本书中学到的内容的一个概述,因为我将在随后的章节中更详细地讨论这些密码原语中的每一个。
1.4.1 密钥交换或如何获得共享秘密
我们将要看的第一个非对称密码学原语是密钥交换。首次发现并发布的公钥算法是一种以其作者命名的密钥交换算法,称为 Diffie-Hellman(DH)。DH 密钥交换算法的主要目的是在两个参与方之间建立一个共同的秘密。然后可以将这个共同的秘密用于不同的目的(例如,作为对称加密原语的密钥)。
在第五章中,我将解释 Diffie-Hellman 的工作原理,但在此简介中,让我们使用一个简单的类比来理解密钥交换提供了什么。像密码学中的许多算法一样,密钥交换必须从参与者使用的一组共同参数开始。在我们的类比中,我们简单地让 Alice 女王和 Bob 勋爵同意使用一个正方形(■)。接下来的步骤是让他们选择自己的随机形状。他们俩都去各自的秘密地点,在不被看到的情况下,Alice 女王选择了一个三角形(▲),而 Bob 勋爵选择了一个星形(★)。他们选择的对象必须以任何代价保持秘密!这些对象代表他们的私钥(见图 1.5)。

图 1.5 DH(Diffie-Hellman)密钥交换的第一步是让两个参与者生成一个私钥。在我们的类比中,Alice 女王选择一个三角形作为她的私钥,而 Bob 勋爵选择一个星形作为他的私钥。
一旦他们选择了他们的私钥,他们都会单独将他们的秘密形状与他们最初同意使用的共同形状(正方形)相结合。这些组合产生了代表他们的公钥的独特形状。Alice 女王和 Bob 勋爵现在可以交换他们的公钥(因此称为密钥交换),因为公钥被视为公共信息。我在图 1.6 中说明了这一点。

图 1.6 DH 密钥交换的第二步,两个参与者交换他们的公钥。参与者通过将他们的私钥与一个共同形状相结合来导出他们的公钥。
现在我们开始看到为什么这个算法被称为公钥算法。这是因为它需要一个由私钥和公钥组成的 密钥对。DH 密钥交换算法的最后一步非常简单:Alice 女王取 Bob 男爵的公钥并与她的私钥结合。Bob 男爵也同样对待 Alice 女王的公钥,并将其与自己的私钥结合。结果现在应该在每一方都是相同的;在我们的示例中,是一个形状结合了星形、正方形和三角形(见图 1.7)。

图 1.7 DH 密钥交换的最后一步,两个参与者产生相同的共享密钥。为此,Alice 女王将她的私钥与 Bob 男爵的公钥结合,而 Bob 男爵则将他的私钥与 Alice 女王的公钥结合。仅观察公钥无法获取共享密钥。
现在由协议参与者决定如何使用这个共享密钥。在本书中,你会看到几个示例,但最明显的场景是在需要共享密钥的算法中使用它。例如,Alice 女王和 Bob 男爵现在可以使用共享密钥作为对称加密原语进一步加密消息的密钥。概括一下
-
Alice 和 Bob 交换他们的公钥,这掩盖了他们各自的私钥。
-
使用另一方的公钥和各自的私钥,他们可以计算出一个共享密钥。
-
观察公钥交换的对手没有足够的信息来计算共享密钥。
注意 在我们的示例中,最后一点很容易被绕过。实际上,在没有任何私钥知识的情况下,我们可以将公钥组合在一起生成共享密钥。幸运的是,这只是我们比喻的一个局限性,但它足以帮助我们理解密钥交换的作用。
实际上,DH 密钥交换非常不安全。你能花几秒钟想出为什么吗?
因为 Alice 女王接受她收到的任何公钥都是 Bob 男爵的公钥,所以我可以拦截交换并用我的公钥替换它,这样我就可以冒充 Bob 男爵向 Alice 女王发起攻击(同样也可以对 Bob 男爵进行相同操作)。我们称之为 中间人 (MITM)攻击者可以成功攻击协议。我们如何解决这个问题?在后面的章节中,我们将看到我们要么需要用另一个加密原语增强此协议,要么需要事先知道 Bob 男爵的公钥是什么。但那样的话,我们不是回到了原点吗?
以前,Alice 女王和 Bob 男爵需要知道一个共享密钥;现在 Alice 女王和 Bob 男爵需要知道各自的公钥。他们如何知道呢?这是不是又是一个鸡生蛋蛋生鸡的问题?嗯,有点像。正如我们将看到的,实际上,公钥密码学并不能解决信任问题,但它简化了其建立(特别是当参与者数量很多时)。
让我们暂停一下,继续下一节,因为你将在第五章了解更多关于密钥交换的知识。我们还有一些非对称加密原语需要揭示(见图 1.8),以完成我们对现实世界密码学的概览。

图 1.8 我们到目前为止学到的加密算法。两大类加密算法是对称加密(使用对称加密)和非对称加密(使用密钥交换)。
1.4.2 非对称加密,不像对称加密那样
DH 密钥交换算法的发明很快被 RSA 算法的发明紧随其后,该算法以 Ron Rivest、Adi Shamir 和 Leonard Adleman 命名。RSA 包含两种不同的原语:公钥加密算法(或非对称加密)和(数字)签名方案。这两种原语都是更大类别的加密算法称为非对称加密的一部分。在本节中,我们将解释这些原语的作用以及它们如何有用。
第一个,非对称加密,与我们之前讨论的对称加密算法有类似的目的:它允许加密消息以获得机密性。然而,与对称加密不同,对称加密是完全不同的:
-
它使用两个不同的密钥:一个公钥和一个私钥。
-
它提供了一个不对称的观点:任何人都可以使用公钥加密,但只有私钥的所有者可以解密消息。
现在让我们用一个简单的类比来解释如何使用非对称加密。我们再次从我们的朋友女王爱丽丝开始,她持有一个私钥(及其相关的公钥)。让我们把她的公钥想象成一个她向公众发布供任何人使用的开放箱子(见图 1.9)。

图 1.9 为了使用非对称加密,女王爱丽丝需要先发布她的公钥(这里用一个开放的盒子表示)。现在,任何人都可以使用这个公钥来加密发送消息给她。而且她应该能够使用相关的私钥解密它们。
现在,你、我和每个想要的人都可以使用她的公钥加密一条消息给她。在我们的类比中,想象一下你会把你的消息插入到开放的箱子里,然后关闭它。一旦箱子关闭了,除了女王爱丽丝之外,没有人能够打开它。这个盒子有效地保护了消息的保密性免受观察者的观察。然后,关闭的盒子(或加密内容)可以发送给女王爱丽丝,她可以使用她的私钥(只有她知道的)来解密它们(见图 1.10)。

图 1.10 非对称加密:(1)任何人都可以使用艾丽丝女王的公钥将消息加密给她。(2)接收后,(3)她可以使用相关联的私钥解密内容。在消息发送给艾丽丝女王时,没有人能够观察到。
让我们在图 1.11 中总结到目前为止我们学到的加密原语。我们只需要再学习一个就可以完成我们的真实世界加密之旅了!

图 1.11 到目前为止我们学到的加密算法:两类大型加密算法是对称加密(使用对称加密)和非对称加密(使用密钥交换和非对称加密)。
1.4.3 数字签名,就像你的纸笔签名一样
我们看到 RSA 提供了一种非对称加密算法,但正如我们之前提到的,它也提供了一种数字签名算法。这一数字签名的加密原语的发明在建立我们世界的爱丽丝和鲍勃之间的信任方面帮助巨大。它类似于真实的签名;你知道的,比如当你试图租一间公寓时,你被要求在合同上签字的那种。
“如果他们伪造我的签名怎么办?”你可能会问,实际上,真实的签名在现实世界中并不提供太多安全性。另一方面,加密签名可以以同样的方式使用,但提供带有你名字的加密证书。你的加密签名是无法伪造的,并且可以很容易地被其他人验证。与你过去在支票上写的古老签名相比,非常有用!
在图 1.12 中,我们可以想象一个协议,艾丽丝女王想向大卫勋爵表明她信任鲍勃勋爵。这是一个典型的多参与者环境下建立信任的例子,以及非对称加密如何帮助。通过签署一份包含“我,艾丽丝女王,信任鲍勃勋爵”的文件,艾丽丝女王可以表明立场并通知大卫勋爵要信任鲍勃勋爵。如果大卫勋爵已经信任艾丽丝女王及其签名算法,那么他可以选择相应地信任鲍勃勋爵。

图 1.12 大卫勋爵已经信任艾丽丝女王。因为艾丽丝女王信任鲍勃勋爵,所以大卫勋爵能够安全地信任鲍勃勋爵吗?
更详细地说,艾丽丝女王可以使用 RSA 签名方案和她的私钥签署消息“我,艾丽丝女王,信任鲍勃勋爵”。这将生成一个看起来像随机噪音的签名(见图 1.13)。

图 1.13 要签署一条消息,艾丽丝女王使用她的私钥并生成一个签名。
任何人都可以通过组合验证签名:
-
艾丽丝的公钥
-
签名的消息
-
签名
结果要么是true(签名有效),要么是false(签名无效),如图 1.14 所示。

图 1.14 要验证来自阿丽斯女王的签名,还需要被签名的消息和阿丽斯女王的公钥。结果要么验证签名,要么无效化签名。
我们现在学到了三种不同的非对称基元:
-
与迪菲-赫尔曼(Diffie-Hellman)进行密钥交换
-
非对称加密
-
使用 RSA 进行数字签名
这三种密码算法是非对称加密中最知名和常用的基元。它们如何帮助解决现实问题可能并不完全明显,但请放心,它们每天都被许多应用程序用来保护周围的事物。现在是时候用我们迄今学到的所有密码算法来完整地描绘我们的图景了(见图 1.15)。

图 1.15 我们迄今学到的对称和非对称算法
1.5 对加密进行分类和抽象
在前一节中,我们调查了两类大型算法:
-
对称加密(或秘密密钥加密)—使用单个秘密。如果有多个参与者知道秘密,则称为共享秘密。
-
非对称加密(或公钥加密)—参与者对于密钥有不对称的视角。例如,有些人会知道公钥,而有些人会同时知道公钥和私钥。
对称和非对称加密不是加密中唯一的两类基元,而且很难对不同的子领域进行分类。但是,正如你将意识到的那样,我们书中的很大一部分内容都是关于(并且利用了)对称和非对称基元。这是因为当今加密中有用的很大一部分内容都包含在这些子领域中。另一种划分加密的方式可能是
-
基于数学的构建—这些依赖于数学问题,如分解数字。(RSA 算法用于数字签名和非对称加密就是这种构建的一个例子。)
-
启发式构建—这些依赖于密码分析人员的观察和统计分析。(对称加密的 AES 就是这种构建的一个例子。)
这种分类还涉及速度因素,因为基于数学的构建通常比基于启发式的构建慢得多。给你一个概念,对称构建通常基于启发式(看起来有效的东西),而大多数非对称构建基于数学问题(被认为是困难的问题)。
对我们来说,严格分类密码学所能提供的一切是很困难的。事实上,关于这个主题的每本书或课程都给出了不同的定义和分类。最终,这些区别对我们来说并不太有用,因为我们将看到大多数密码原语都是具有独特 安全声明 的独特工具。我们反过来可以使用这些工具中的许多作为构建协议的基础模块。因此,了解这些工具的每一个是如何工作的,以及它们提供了哪些安全声明,以便理解它们如何保护我们周围的协议,是非常重要的。因此,这本书的第一部分将介绍最有用的密码原语及其安全属性。
书中的很多概念第一次接触时可能会相当复杂。但像一切事物一样,我们越是阅读它们,越是在上下文中看到它们,它们就越自然,我们就能越抽象它们。这本书的作用是帮助你创建抽象,让你建立这些构造所做的事情的心理模型,并理解它们如何组合在一起产生安全协议。我经常会谈论构造的接口,并给出使用和组合的现实示例。
以前,密码学的定义很简单:女王爱丽丝和博伯爵想要交换秘密信息。现在不再是这样了。如今的密码学描述相当复杂,是围绕着发现、突破和实际需求有机发展起来的。归根结底,密码学是帮助增强协议以使其在对抗环境中运行的东西。
要准确理解密码学如何帮助,对我们而言最重要的是这些协议旨在实现的一系列目标。那才是有用的部分。本书中我们将了解的大多数密码原语和协议提供以下一种或两种属性:
-
保密性 —— 它关乎掩盖和保护一些信息免受错误眼睛的侵害。例如,加密掩盖了传输中的消息。
-
认证 —— 它关乎我们正在与谁交谈。例如,这有助于确保我们收到的消息确实来自女王爱丽丝。
当然,这仍然是密码学可以提供的内容的一个重要简化。在大多数情况下,细节都在原语的安全声明中。根据我们在协议中如何使用密码原语,它将实现不同的安全属性。
在本书中,我们将学习新的加密原语以及它们如何结合起来以暴露诸如保密性和认证等安全属性。目前,我们要欣赏的是,密码学是关于在对抗性环境中为协议提供保险的。虽然“对手”并没有明确定义,但我们可以想象他们是试图破坏我们协议的人:参与者、观察者、中间人。他们反映了真实生活中对手可能的情况。因为最终,密码学是一个实践领域,旨在防御血肉和骨头以及位的不良行为者。
1.6 理论密码学与现实世界密码学
1993 年,布鲁斯·施奈尔(Bruce Schneier)发布了《应用密码学》(Wiley),这是一本针对希望构建涉及密码学应用的开发人员和工程师的书籍。大约在 2012 年,肯尼·帕特森(Kenny Paterson)和奈杰尔·斯马特(Nigel Smart)开始了一年一度的名为真实世界密码(Real World Crypto)的会议,针对的是同一群人。但是应用密码学和现实世界密码学是指什么?是否有多种类型的密码学?
要回答这些问题,我们必须从定义理论密码学开始,这是密码学家和密码分析家从事的密码学。这些密码学人大多来自学术界,在大学工作,但有时来自行业或政府的特定部门。他们研究密码学的一切。结果通过国际期刊和会议的出版物和演示分享。然而,他们所做的并不是显然有用或实用的。通常情况下,没有“概念证明”或代码被发布。无论如何,这是毫无意义的,因为没有计算机足够强大来运行他们的研究。话虽如此,理论密码学有时变得如此有用和实用,以至于它会进入另一边。
另一方面是应用密码学或现实世界密码学的世界。它是你周围所有应用程序中发现的安全的基础。虽然它通常看起来好像不存在,几乎是透明的,但当你在互联网上登录银行账户时它就在那里;当你给朋友发消息时它与你同在;当你丢失手机时它帮助保护你。它是无处不在的,因为不幸的是,攻击者无处不在,并积极尝试观察和伤害我们的系统。从业者通常来自行业,但有时会与学术界合作评估算法并设计协议。结果通常通过会议、博客文章和开源软件分享。
现实世界的密码学通常非常关注现实世界的考虑因素:算法提供的确切安全级别是多少?运行算法需要多长时间?原语需要的输入和输出大小是多少?现实世界的密码学就是这本书的主题。虽然理论密码学是其他书的主题,但我们仍将在本书的最后几章中窥探一下那里正在酝酿的东西。准备好被惊讶吧,因为你可能会一瞥到明天的现实世界的密码学。
现在你可能想知道:开发人员和工程师如何选择用于他们的现实世界应用的密码学?
1.7 从理论到实践:选择你自己的冒险
位于顶部的是提出并解决难题的密码分析师[…] 而在底部的是希望加密一些数据的软件工程师。
—Thai Duong(“那么你想自己设计密码学?”,2020)
在我花费在研究和从事密码学的所有年份中,我从未注意到一个密码学原语在实际应用中被使用的单一模式。情况相当混乱。在一个理论原语被采用之前,有一长串人要处理这个原语,并将其塑造成某种可消费的东西,有时对大众更安全。我该如何向你解释呢?
你听说过选择你自己的冒险吗?这是一个旧书系列,你可以选择如何沿着故事前进。原则很简单:你读完书的第一部分;在部分结束时,书让你通过给出不同的选项来决定未来的道路。每个选项都与一个不同的部分号码相关,如果你愿意,可以直接跳转到该部分。所以,在这里我也做了同样的事情!从阅读下一段开始,按照它给出的方向前进。
一切始于此。 你是谁?你是爱丽丝,一位密码学家吗?你是大卫,私营行业工作者,需要解决问题吗?还是你是伊娃,工作在政府部门,忙于密码学?
-
你是爱丽丝,前往步骤 1。
-
你是大卫,前往步骤 2。
-
你是伊娃,前往步骤 3。
步骤 1:研究员得研究。 你是一名在大学工作的研究人员,或者在私营公司或非营利组织的研究团队工作,或者在像 NIST 或 NSA 这样的政府研究机构工作。因此,你的资金可能来自不同的地方,并可能激励你研究不同的东西。
-
你发明了一个新的原语,前往步骤 4。
-
你发明了一种新的结构,前往步骤 5。
-
你开始了一场公开竞赛,前往步骤 6。
第 2 步:行业有需求。 作为你的工作的一部分,出现了一些问题,你需要一个新的标准。例如,Wi-Fi 联盟是由感兴趣的公司资助的非营利组织,制定了围绕 Wi-Fi 协议的一套标准。另一个例子是银行联合起来制定了支付卡行业数据安全标准(PCI-DSS),该标准强制执行处理信用卡号码时要使用的算法和协议。
-
你决定资助一些急需的研究,前往第 1 步。
-
你决定标准化一个新的基元或协议,前往第 5 步。
-
你发起了一场公开竞赛,前往第 6 步。
第 3 步:政府有需求。 你为你国家的政府工作,需要推出一些新的加密。例如,NIST 负责发布联邦信息处理标准(FIPS),规定了哪些加密算法可以被与美国政府打交道的公司使用。虽然许多这些标准都是成功案例,人们倾向于对政府机构推动的标准有很多信任,但(不幸的是)对于失败还有很多话要说。
在 2013 年,根据爱德华·斯诺登的披露,发现 NSA 故意并成功地推动在标准中包含后门算法(参见 Bernstein 等人的“Dual EC: A Standardized Back Door”),其中包括一个隐藏的开关,允许 NSA,仅限 NSA,预测你的秘密。这些后门可以被视为魔法密码,允许政府(仅限政府,据说)颠覆你的加密。在此之后,密码学界对来自政府机构的标准和建议失去了很多信心。最近,在 2019 年,发现俄罗斯标准 GOST 也遭受了同样的对待。
密码学家长期以来一直怀疑,该机构在 2006 年被国家标准技术研究所采纳并后来被国际标准化组织采纳的标准中植入了漏洞,该组织有 163 个成员国。机密的 N.S.A.备忘录似乎证实了这个致命弱点,由 2007 年两名微软密码学家发现,由该机构设计。N.S.A.编写了这一标准,并积极推动国际组织,私下称这一努力为“一项精湛的挑战”。。
—纽约时报(“N.S.A. Able to Foil Basic Safeguards of Privacy on Web,” 2013)
-
你资助了一些研究,前往第 1 步。
-
你组织了一场公开竞赛,前往第 6 步。
-
你推动正在使用的基元或协议的标准化,前往第 7 步。
第 4 步:提出一个新概念。 作为研究人员,你成功做到了不可能的事情;你发明了一个新概念。当然,有人已经想到了加密,但在密码学领域每年仍然会提出一些新的原语。其中一些将被证明无法实现,而一些将最终得以解决。也许你的提议中有一个实际的构造,或者也许你得等待看看是否有人能想出有效的方法。
-
你的原始构造被实施,前往第 5 步。
-
你的原始构造最终无法实施,回到起点。
第 5 步:提出新的构造或协议。 一个密码学家或密码学家团队提出了一个实现概念的新算法。例如,AES 是加密方案的一种实例化。(AES 最初由文森特·瑞曼和约安·达门提出,他们将他们的构造命名为他们的名字的缩写,Rijndael。)接下来呢?
-
有人在你的构造基础上进行改进,前往第 5 步。
-
你参加了一个公开竞赛并赢得了胜利!前往第 6 步。
-
对你的工作有很多炒作;你将获得一个标准!前往第 7 步。
-
你决定对你的构造进行专利申请,前往第 8 步。
-
你或其他人决定实现你的构造会很有趣。前往第 9 步。
第 6 步:一个算法赢得了比赛。 密码学家们最喜欢的过程是一个公开的竞赛!例如,AES 就是一个邀请全球研究者参与的竞赛。经过数十次提交和分析以及密码分析师的帮助(可能需要数年),候选名单被缩减到几个(在 AES 的情况下,只有一个),然后开始标准化过程。
-
你很幸运,在多年的竞争后,你的构造赢得了胜利!前往第 7 步。
-
不幸的是,你失败了。回到起点。
第 7 步:一个算法或协议被标准化。 标准通常由政府或标准化机构发布。目的是确保每个人都在同一页面上,以最大限度地提高互操作性。例如,NIST 定期发布密码学标准。密码学中的一个知名标准化机构是互联网工程任务组(IETF),它是互联网上许多标准(如 TCP、UDP、TLS 等)的背后推动者,在本书中你会经常听到。在 IETF 中,标准称为 请求评论(RFC),几乎任何想要制定标准的人都可以编写。
为了加强我们不投票的观念,我们还采用了“哼声”的传统:例如,当我们面对面开会时,工作组主席想要了解“房间的感觉”时,主席有时会要求每一方对特定问题哼唱,“支持”还是“反对”。
—RFC 7282(《关于 IETF 中的共识和哼声》,2014)
有时,一家公司直接发布一个标准。例如,RSA 安全有限责任公司(由 RSA 算法的创建者资助)发布了一系列 15 个名为 公钥密码学标准(PKCS)的文档,以合法化该公司当时使用的算法和技术。如今,这种情况非常罕见,许多公司通过 IETF 来标准化他们的协议或算法,而不是通过自定义文档。
-
你的算法或协议得到了实现,前往步骤 9。
-
没有人关心你的标准,回到起点。
步骤 8:专利到期。 在密码学中,专利通常意味着没有人会使用该算法。一旦专利过期,重新对原语产生兴趣并不罕见。最著名的例子可能是 Schnorr 签名,它曾是最受欢迎的签名方案之一,直到 Schnorr 本人在 1989 年对算法进行了专利。这导致 NIST 标准化了一个较差的算法,称为数字签名算法(DSA),它成为了当时的首选签名方案,但现在已经不太使用。Schnorr 签名的专利在 2008 年到期,自那时起该算法开始重新受到关注。
-
时间过去太久了,你的算法将永远被遗忘。回到起点。
-
你的构建启发了更多的构建被发明在其之上,前往步骤 5。
-
现在人们想要使用你的构建,但在真正标准化之前不会这样。前往步骤 7。
-
一些开发人员正在实现你的算法!前往步骤 9。
步骤 9:构建或协议被实现。 实现者不仅要解读论文或标准(尽管标准 应该 面向实现者),而且还必须使他们的实现易于使用和安全。这并不总是一件简单的任务,因为在使用密码学的方式上可能会出现许多灾难性的错误。
-
有人决定是时候为这些实现提供一个标准支持了。没有标准支持是令人尴尬的。前往步骤 7。
-
炒作正落在你的加密库头上!前往步骤 10。
步骤 10:开发人员在应用程序中使用协议或原语。 开发人员有一个需求,而你的加密库似乎解决了这个需求 —— 轻而易举!
-
原语解决了需求,但它没有一个标准。不太好。前往步骤 7。
-
我希望这是用我的编程语言编写的。前往步骤 9。
-
我滥用了库或者构建已经损坏。游戏结束。
你成功了!原语实现到真实世界有很多方式。最好的方式涉及多年的分析,一个友好的实现标准和优秀的库。更糟糕的方式涉及一个糟糕的算法和糟糕的实现。在图 1.16 中,我说明了首选路径。

图 1.16 理想的加密算法生命周期始于密码专家在白皮书中实例化一个概念。例如,AES 是对称加密概念的一个实例化(还有许多其他对称加密算法)。然后可以对构造进行标准化:每个人都同意以某种方式实现它以最大程度地实现互操作性。然后通过在不同语言中实现标准来创建支持。
1.8 一个警告
任何人,从最无知的业余爱好者到最优秀的密码学家,都可以创建一个他自己无法破解的算法。
—布鲁斯·施奈尔(“给业余密码设计者的备忘录”,1998 年)
我必须警告您,密码学的艺术很难掌握。一旦您完成了这本书,就假设您可以构建复杂的密码协议是不明智的。这段旅程应该启发您,向您展示可能性,并向您展示事物是如何运作的,但它不会使您成为密码学大师。
本书并非圣杯。事实上,本书的最后几页将带你走过最重要的一课——不要独自踏上真正的冒险。龙可以杀人,你需要一些支持来陪伴你以便击败它们。换句话说,密码学很复杂,而仅凭本书无法让您滥用所学知识。要构建复杂的系统,需要研究自己的行业多年的专家。相反,您将学到的是如何识别何时应使用密码学,或者,如果有什么不对劲,可以使用什么密码原语和协议来解决您面临的问题,以及所有这些密码算法在表面下是如何工作的。既然您已经被警告,请转到下一章。
摘要
-
协议是一个逐步指南,在其中多个参与者尝试实现类似交换保密消息之类的目标。
-
密码学是关于增强协议以在对抗性环境中保护它们。它通常需要秘密。
-
密码原语是一种密码算法类型。例如,对称加密是一种密码原语,而 AES 是一种特定的对称加密算法。
-
对不同的密码原语进行分类的一种方法是将它们分为两种类型:对称和非对称密码学。对称密码学使用单一密钥(正如您在对称加密中所看到的),而非对称密码学则使用不同的密钥(正如您在密钥交换、非对称加密和数字签名中所看到的)。
-
密码学属性难以分类,但它们通常旨在提供以下两种属性之一:身份验证或保密性。身份验证涉及验证某物或某人的真实性,而保密性涉及数据或身份的隐私。
-
现实世界的密码学很重要,因为它在技术应用中无处不在,而理论密码学在实践中通常不那么有用。
-
本书中包含的大多数密码学基元是经过长时间的标准化过程达成一致的。
-
密码学很复杂,在实施或使用密码学基元时存在许多危险。
第二章:哈希函数
本章内容包括
-
哈希函数及其安全属性
-
当今广泛采用的哈希函数
-
存在的其他类型的哈希函数
将全局唯一标识符分配给任何东西,这就是您将在本章中学到的第一个密码构造的承诺——哈希函数。哈希函数在密码学中随处可见——随处可见!非正式地说,它们以您希望的任何数据作为输入,并返回一个唯一的字节串。给定相同的输入,哈希函数始终会产生相同的字节串。这可能看起来像无足轻重的事情,但这个简单的构造在构建密码学中的许多其他构造时非常有用。在本章中,您将学到有关哈希函数的一切以及它们为什么如此多才多艺。
2.1 什么是哈希函数?
在你面前,一个下载按钮占据了页面的很大一部分。您可以读到字母DOWNLOAD,点击这个似乎会将您重定向到包含文件的不同网站。下面是一长串难以理解的字母:
f63e68ac0bf052ae923c03f5b12aedc6cca49874c1c9b0ccf3f39b662d1f487b
紧接着是一个看起来像是某种首字母缩写的东西:sha256sum。听起来耳熟吗?你可能在以前的生活中下载过一些伴随着这样奇怪字符串的东西(见图 2.1)。

图 2.1 一个链接到包含文件的外部网站的网页。外部网站无法修改文件的内容,因为第一页提供了文件的哈希或摘要,这确保了下载的文件的完整性。
如果您曾经想知道那串长字符串要做什么:
-
点击按钮下载文件
-
使用 SHA-256 算法对下载的文件进行哈希处理
-
将输出(摘要)与网页上显示的长字符串进行比较
这使您能够验证您下载了正确的文件。
注 哈希函数的输出通常称为摘要或HASH。我在本书中交替使用这两个词。其他人可能称其为校验和或和,但我避免使用这些术语,因为这些术语主要用于非密码哈希函数,可能会导致更多的混淆。当不同的代码库或文档使用不同的术语时,请记住这一点。
要尝试对某些东西进行哈希处理,您可以使用流行的 OpenSSL 库。它提供了一个多功能的命令行界面(CLI),在包括 macOS 在内的许多系统中默认提供。例如,可以通过打开终端并输入以下命令来完成这项工作:
$ openssl dgst -sha256 downloaded_file
f63e68ac0bf052ae923c03f5b12aedc6cca49874c1c9b0ccf3f39b662d1f487b
通过该命令,我们使用了 SHA-256 哈希函数将输入(下载的文件)转换为一个唯一标识符(命令所回显的值)。这些额外的步骤提供了什么?它们提供了完整性和真实性。它告诉你,你下载的确实是你打算下载的文件。
所有这些都是由哈希函数的一个安全属性实现的,称为第二原像抗性。这个数学启发的术语意味着从哈希函数的长输出中,f63e...,你不能找到另一个会散列到相同输出f63e....的文件。在实践中,这意味着这个摘要与您正在下载的文件紧密相关,并且没有攻击者应该能够通过给您不同的文件来愚弄您。
十六进制表示
顺便说一句,长输出字符串f63e...表示十六进制中显示的二进制数据(一种基于 16 的编码,使用数字 0 到 9 和字母 a 到 f 来表示几位数据)。我们可以用 0 和 1(基数 2)来显示二进制数据,但这将占用更多的空间。相反,十六进制编码允许我们为每 8 位(1 字节)遇到的数据写 2 个字母数字字符。它对人类来说有点可读,并且占用更少的空间。有其他方式来为人类消费编码二进制数据,但最广泛使用的两种编码是十六进制和 base64。基数越大,显示二进制字符串所需的空间就越少,但在某些时候,我们会用完人类可读的字符。
请注意,这个长摘要由网页的所有者(们)控制,任何可以修改网页的人都可以轻松地替换它。(如果你还不相信,请花点时间考虑一下。)这意味着我们需要信任给我们摘要的页面,它的所有者以及用于检索页面的机制(尽管我们不需要信任给我们下载文件的页面)。在这个意义上,哈希函数本身并不提供完整性。下载文件的完整性和真实性来自于与给出摘要的受信任机制的摘要结合起来(在本例中是 HTTPS)。我们将在第九章讨论 HTTPS,但现在,想象它神奇地允许你与网站安全通信。
回到我们的哈希函数,它可以被可视化为图 2.2 中的黑匣子。我们的黑匣子接受单个输入并产生单个输出。

图 2.2 哈希函数接受任意长度的输入(文件、消息、视频等)并产生固定长度的输出(例如,SHA-256 的 256 位)。对相同输入进行哈希处理会产生相同的摘要或哈希。
这个函数的输入可以是任意大小。它甚至可以是空的。输出始终具有相同的长度和确定性:如果给定相同的输入,它总是产生相同的结果。在我们的例子中,SHA-256 始终提供 256 位(32 字节)的输出,始终以十六进制的 64 个字母数字字符编码。哈希函数的一个主要特性是不能逆转算法,这意味着不能仅凭输出就找到输入。我们说哈希函数是单向的。
为了说明哈希函数在实践中是如何工作的,我们将使用相同的 OpenSSL CLI 对不同的输入使用 SHA-256 哈希函数进行哈希。以下终端会话显示了这一点。
$ echo -n "hello" | openssl dgst -sha256
2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824
$ echo -n "hello" | openssl dgst -sha256 // ❶
2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824
$ echo -n "hella" | openssl dgst -sha256 // ❷
70de66401b1399d79b843521ee726dcec1e9a8cb5708ec1520f1f3bb4b1dd984
$ echo -n "this is a very very very very very very // ❸
➥ very very very long sentence" | openssl dgst -sha256 // ❸
1166e94d8c45fd8b269ae9451c51547dddec4fc09a91f15a9e27b14afee30006
❶ 对相同输入进行哈希会产生相同的结果。
❷ 输入中的微小变化会完全改变输出。
❸ 输出始终相同大小,无论输入大小如何。
在下一节中,我们将看到哈希函数的确切安全性质是什么。
2.2 哈希函数的安全性质
应用密码学中的哈希函数是常见的构造,通常被定义为提供三种特定安全性质。随着我们将在接下来的部分中看到的,这个定义随着时间的推移而改变。但是现在,让我们定义构成哈希函数的三个强基础。这很重要,因为您需要了解哈希函数可以在哪里有用,以及它们不起作用的地方。
第一个是原像抗性。这个属性确保没有人应该能够反转哈希函数以恢复给定输出的输入。在图 2.3 中,我们通过想象我们的哈希函数就像一个搅拌机,使得从制作的冰沙中恢复原料变得不可能。

图 2.3 给定哈希函数产生的摘要(这里表示为搅拌机),逆转它并找到使用的原始输入是不可能的(或者在技术上如此困难,我们假设永远不会发生)。这种安全性质被称为原像抗性。
警告 如果您的输入很小,这是真的吗?假设它是oui或non,那么有人很容易对所有可能的 3 个字母单词进行哈希,找出输入是什么。如果您的输入空间很小呢?意味着您总是对句子的变体进行哈希,例如,“我将在星期一凌晨 3 点回家。”在这种情况下,一个人可以预测这一点,但不知道确切的星期几或小时,仍然可以对所有可能的句子进行哈希,直到产生正确的输出。因此,这个第一个原像安全性质有一个明显的警告:您无法隐藏太小或可预测的东西。
第二个属性是第二原像抗性。当我们想要保护文件的完整性时,我们已经看到了这个安全性质。该属性表明:如果我给你一个输入和它哈希到的摘要,你不应该能够找到一个不同的输入,其哈希到相同的摘要。图 2.4 说明了这个原则。

图 2.4 考虑一个输入及其相关的摘要,一个人永远不应该能够找到一个不同的输入,其哈希值相同。这种安全性质被称为第二原像抗性。
请注意我们无法控制第一个输入。这种强调对于理解哈希函数的下一个安全性质非常重要。
最后,第三个属性是碰撞抗性。它保证没有人能够产生两个不同的输入,其哈希为相同的输出(如图 2.5 所示)。在这里,攻击者可以选择两个输入,不像前一个属性固定了其中一个输入。

图 2.5 永远不应该找到两个输入(在左侧表示为两个随机数据块)哈希为相同的输出值(在右侧)。这种安全属性称为碰撞抗性。
人们经常混淆碰撞抗性和第二原像抗性。花点时间理解它们的区别。
随机预言机
另外,哈希函数通常设计成它们的摘要是不可预测和随机的。这是有用的,因为人们并不总是能够证明一个协议是安全的,多亏了我们讨论过的哈希函数的安全属性之一(比如碰撞抗性,例如)。许多协议实际上是在随机预言机模型中被证明的,在这种协议中,一个名为随机预言机的虚构和理想的参与者被使用。在这种类型的协议中,可以将任何输入作为请求发送给该随机预言机,据说它以完全随机的输出作为响应返回,并且像哈希函数一样,给它相同的输入两次会返回相同的输出两次。
在这个模型中的证明有时是有争议的,因为我们不确定我们是否可以用真实的哈希函数(在实践中)替换这些随机预言机。然而,许多合法的协议是通过这种方法被证明是安全的,其中哈希函数被视为比它们实际上更理想的东西。
2.3 哈希函数的安全考虑
到目前为止,我们看到了哈希函数的三个安全属性:
-
原像抗性
-
第二原像抗性
-
碰撞抗性
这些安全属性通常单独来看毫无意义;一切都取决于你如何使用哈希函数。尽管如此,重要的是在我们看一些现实世界的哈希函数之前,我们要理解这里的一些限制。
首先,这些安全属性假定你(合理地)使用哈希函数。想象一下,我要么对单词yes进行哈希,要么对单词no进行哈希,然后我发布摘要。如果你对我在做什么有一些想法,你可以简单地对这两个词进行哈希,并将结果与我给你的结果进行比较。因为没有涉及到任何秘密,而且我们使用的哈希算法是公开的,所以你可以这样做。事实上,你可能会认为这会破坏哈希函数的前像抗性,但我会认为你的输入不够“随机”。此外,由于哈希函数接受任意长度的输入并始终产生相同长度的输出,也有无限数量的输入哈希到相同的输出。同样,你可能会说,“嗯,这不是在破坏第二前像抗性吗?”第二前像抗性仅仅是说找到另一个输入是极其困难的,困难到我们认为在实践中是不可能的,但在理论上是可能的。
其次,摘要的大小确实很重要。这并不是哈希函数的奇特之处。在实践中,所有的加密算法都必须关心它们参数的大小。让我们想象一下以下极端情况。我们有一个哈希函数,它以均匀随机的方式生成长度为 2 位的输出(意味着它将00作为输出的概率为 25%,01为 25%,以此类推)。你不需要做太多工作就能产生碰撞:在对几个随机输入字符串进行哈希之后,你应该能够找到两个哈希到相同输出的字符串。因此,哈希函数在实践中必须产生的最小输出大小是 256 位(或 32 字节)。有了这么大的输出,除非计算方面发生突破,否则碰撞应该是不可能的。
这个数字是怎么得到的呢?在实际的密码学中,算法的目标是提供至少 128 位的安全性。这意味着一个想要攻破算法(提供 128 位安全性)的攻击者必须执行大约 2128 次操作(例如,尝试所有长度为 128 位的可能输入字符串将需要 2128 次操作)。为了让哈希函数提供前面提到的所有三个安全属性,它需要提供至少 128 位的安全性来抵御所有三种攻击。通常,最简单的攻击是由于生日悖论导致的碰撞查找。
生日悖论
生日悖论根源于概率论,其中生日问题揭示了一些不直观的结果。在一个房间里,至少需要多少人才能有至少 50%的机会两人拥有相同的生日(即发生碰撞)。事实证明,随机选择的 23 人就足够达到这个概率!很奇怪,对吧?
这被称为 生日悖论。实际上,当我们从 2^N 个可能性中随机生成字符串时,你可以期望有 50% 的概率在生成约 2^(N/2) 个字符串后发现冲突。
如果我们的哈希函数生成了 256 位的随机输出,所有输出的空间大小为 2²⁵⁶。这意味着在生成了 2¹²⁸ 个摘要之后,可以以较高的概率找到冲突(由于生日悖论)。这是我们的目标数字,这也是哈希函数最少必须提供 256 位输出的原因。
有时某些约束会迫使开发人员通过 截断(移除其中的一些字节)来减小摘要的大小。理论上,这是可能的,但会大大降低安全性。为了至少实现 128 位安全性,摘要不得被截断为:
-
256 位用于防冲突
-
128 位用于前像和第二前像防护
这意味着根据依赖的属性,哈希函数的输出可以被截断以获得更短的摘要。
2.4 实践中的哈希函数
正如我们之前所说的,在实践中,哈希函数很少单独使用。它们通常与其他元素结合在一起,以创建密码原语或密码协议。在本书中,我们将看到许多使用哈希函数构建更复杂对象的例子,但本节描述了在现实世界中哈希函数的几种不同用法。
2.4.1 承诺
想象一下,你知道市场上的一只股票将会增值并在未来一个月达到 50 美元,但由于某种法律原因,你真的不能告诉你的朋友(也许是出于某种法律原因)。尽管如此,你仍然希望能够事后告诉你的朋友你知道这件事,因为你自以为是(不要否认)。你可以做的是承诺一句话,如“股票 X 下个月将达到 50 美元。” 为此,将该句话哈希,并将输出给你的朋友。一个月后,揭示这句话。你的朋友将能够哈希这句话以观察到确实产生了相同的输出。
这就是我们所说的 承诺方案。密码学中的承诺通常试图实现两个属性:
-
隐藏 —— 一个承诺必须隐藏底层值。
-
绑定 —— 一个承诺必须隐藏一个单一值。换句话说,如果你承诺一个值 x,你不应该能够后来成功地透露一个不同的值 y。
练习
如果将哈希函数用作承诺方案,你能否判断它是否提供了隐藏和绑定?
2.4.2 子资源完整性
有时(经常)网页会导入外部 JavaScript 文件。例如,很多网站使用内容传送网络(CDN)在其页面中导入 JavaScript 库或与 web 框架相关的文件。这些 CDN 被放置在战略位置,以便快速向访问者传递这些文件。然而,如果 CDN 走向歧途并决定提供恶意的 JavaScript 文件,这可能是一个真正的问题。为了应对这种情况,网页可以使用一个名为子资源完整性的功能,允许在导入标签中包含摘要:
<script src="https://code.jquery.com/jquery-2.1.4.min.js"
integrity="sha256-8WqyJLuWKRBVhxXIL1jBDD7SDxU936oZkCnxQbWwJVw="></script>
这恰好是我们在本章开头讨论过的情景。一旦检索到 JavaScript 文件,浏览器对其进行哈希处理(使用 SHA-256),并验证其是否与页面中硬编码的摘要相对应。如果验证通过,JavaScript 文件将被执行,因为其完整性已经得到验证。
2.4.3 BitTorrent
世界各地的用户(称为对等体)使用 BitTorrent 协议直接在彼此之间共享文件(我们也称之为点对点)。为了分发一个文件,它被切成块,每个块都被单独散列。然后这些哈希值作为信任源被共享以代表要下载的文件。
BitTorrent 有几种机制允许对等体从不同的对等体获取文件的不同块。最后,通过对下载的每个块进行哈希处理并将输出与各自已知的摘要(在重新组装文件之前)匹配来验证整个文件的完整性。例如,以下“磁铁链接”代表 Ubuntu 操作系统,v19.04。它是通过对文件的元数据以及所有块的摘要进行哈希处理而获得的摘要(以十六进制表示)。
magnet:?xt=urn:btih:b7b0fbab74a85d4ac170662c645982a862826455
2.4.4 Tor
Tor 浏览器的目标是让个人能够匿名浏览互联网。另一个特性是,可以创建隐藏的网页,其物理位置难以追踪。与这些页面的连接通过使用网页的公钥进行保护的协议来保护。(我们将在第九章讨论会话加密时详细了解其工作原理。)例如,Silk Road 曾是毒品的 eBay,直到被 FBI 查封,可以通过 Tor 浏览器中的silkroad6ownowfk .onion访问。这个 base32 字符串实际上代表了 Silk Road 的公钥的哈希值。因此,通过知道洋葱地址,你可以验证你正在访问的隐藏网页的公钥,并确保你正在与正确的页面交流(而不是冒充者)。如果这不清楚,不用担心,我会在第九章再次提到这一点。
练习
顺便说一句,这个字符串不可能代表 256 位(32 字节),对吗?那么根据你在第 2.3 节学到的内容,这样是安全的吗?另外,你能猜到 Dread Pirate Roberts(Silk Road 的网站管理员的化名)是如何获得一个包含网站名称的哈希值的吗?
在本节的所有示例中,哈希函数提供了内容完整性或真实性,用于以下情况:
-
有人可能会篡改被哈希的内容。
-
哈希已经安全地传达给你。
我们有时也会说我们认证某物或某人。重要的是要理解,如果哈希不是安全地获取的,那么任何人都可以用其他内容的哈希替换它!因此,它本身不提供完整性。下一章关于消息认证码将通过引入密钥来修复这一点。现在让我们看看你可以使用哪些实际的哈希函数算法。
2.5 标准化的哈希函数
在我们之前的示例中提到了 SHA-256,这只是我们可以使用的哈希函数之一。在我们继续列出我们这个时代推荐的哈希函数之前,让我们先提到其他在实际应用中人们使用但不被视为加密哈希函数的算法。
首先,像 CRC32 这样的函数不是加密哈希函数,而是错误检测代码函数。虽然它们有助于检测一些简单的错误,但它们没有提供先前提到的任何安全属性,并且不应与我们正在讨论的哈希函数混淆(尽管它们有时可能会共享名称)。它们的输出通常称为校验和。
其次,像 MD5 和 SHA-1 这样的流行哈希函数如今被认为是不安全的。尽管它们曾经是 20 世纪 90 年代的标准和广泛接受的哈希函数,但 MD5 和 SHA-1 在 2004 年和 2016 年被不同研究团队发布的碰撞攻击显示出是不安全的。这些攻击部分成功是因为计算机技术的进步,但主要是因为在哈希函数设计中发现了缺陷。
废弃是困难的
直到研究人员展示了它们缺乏抵抗碰撞的能力之前,MD5 和 SHA-1 都被认为是良好的哈希函数。尽管如今它们的原像和第二原像抵抗力尚未受到任何攻击的影响,但这对我们并不重要,因为我们只想在本书中谈论安全算法。尽管如此,你仍然会看到一些人在只依赖这些算法的原像抵抗力而不依赖它们的碰撞抵抗力的系统中使用 MD5 和 SHA-1。这些人经常争辩说,由于遗留和向后兼容性原因,他们无法将哈希函数升级为更安全的函数。由于本书意在长期存在并成为真实世界密码学未来的一束明亮光芒,这将是我最后一次提到这些哈希函数。
接下来的两个小节介绍了 SHA-2 和 SHA-3,这是两个最广泛使用的哈希函数。图 2.6 介绍了这些函数。

图 2.6 SHA-2 和 SHA-3,两种最广泛采用的哈希函数。SHA-2 基于 Merkle–Damgård 构造,而 SHA-3 基于海绵构造。
2.5.1 SHA-2 哈希函数
现在我们已经了解了哈希函数是什么,也瞥见了它们的潜在用途,接下来需要看看在实践中我们可以使用哪些哈希函数。在接下来的两节中,我介绍了两种广泛接受的哈希函数,并且从内部给出了它们工作的高级解释。这些高级解释不应该提供关于如何使用哈希函数的更深入见解,因为我给出的黑盒描述应该足够了。但尽管如此,了解这些加密原语是如何由密码学家设计的还是很有趣的。
最广泛采用的哈希函数是 安全哈希算法 2(SHA-2)。SHA-2 由 NSA 发明,并于 2001 年由 NIST 标准化。它旨在添加到 NIST 已经标准化的老化的安全哈希算法 1(SHA-1)中。SHA-2 提供了 4 个不同的版本,分别产生输出长度为 224、256、384 或 512 位。它们各自的名称省略了算法的版本:SHA-224、SHA-256、SHA-384 和 SHA-512。此外,另外两个版本,SHA-512/224 和 SHA-512/256,通过截断 SHA-512 的结果分别提供了 224 位和 256 位的输出。
在以下的终端会话中,我们使用 OpenSSL CLI 调用了 SHA-2 的各个变种。请注意,使用相同的输入调用不同的变种会产生完全不同长度的输出。
$ echo -n "hello world" | openssl dgst -sha224
2f05477fc24bb4faefd86517156dafdecec45b8ad3cf2522a563582b
$ echo -n "hello world" | openssl dgst -sha256
b94d27b9934d3e08a52e52d7da7dabfac484efe37a5380ee9088f7ace2efcde9
$ echo -n "hello world" | openssl dgst -sha384
fdbd8e75a67f29f701a4e040385e2e23986303ea10239211af907fcbb83578b3
➥ e417cb71ce646efd0819dd8c088de1bd
$ echo -n "hello world" | openssl dgst -sha512
309ecc489c12d6eb4cc40f50c902f2b4d0ed77ee511a7c7a9bcd3ca86d4cd86f
➥ 989dd35bc5ff499670da34255b45b0cfd830e81f605dcf7dc5542e93ae9cd76f
现在,人们主要使用 SHA-256,它提供了我们三个安全性属性所需的最低 128 位安全性,而更多防范性的应用则使用 SHA-512。现在,让我们看一下 SHA-2 如何工作的简化解释。
异或运算
要理解接下来的内容,你需要理解 XOR(异或)操作。XOR 是位操作,意味着它在位上操作。下图显示了它的工作原理。XOR 在密码学中无处不在,所以确保你记住它。

异或(Exclusive OR 或 XOR,通常表示为 ⊕)操作作用于 2 位。它类似于 OR 操作,但当两个操作数都是 1 时不同。
一切都始于一个称为 压缩函数 的特殊函数。压缩函数接受某些大小的两个输入,并产生一个输入大小的输出。简而言之,它接受一些数据并返回较少的数据。图 2.7 说明了这一点。

图 2.7 压缩函数接受两个不同大小的输入 X 和 Y(这里都是 16 字节),并返回一个大小为 X 或 Y 的输出。
虽然构建压缩函数有不同的方法,但 SHA-2 使用了 Davies–Meyer 方法(见图 2.8),它依赖于一个 分组密码(可以加密固定大小的数据块的密码)。我在第一章中提到了 AES 分组密码,但你还没有学习过它。目前,接受压缩函数是一个黑盒,直到你在第四章中学习了认证加密。

图 2.8 展示了通过戴维斯-迈耶构造构建的压缩函数的示意图。压缩函数的第一个输入(输入块)用作块密码的密钥。第二个输入(中间值)用作要由块密码加密的输入。然后,它再次通过与块密码的输出进行异或来使用自身。
SHA-2 是一种默克尔-达姆高构造,这是一种通过迭代调用这样的压缩函数对消息进行哈希的算法(由拉尔夫·默克尔和伊万·达姆高独立发明)。具体而言,它通过以下两个步骤进行。
首先,它对我们要哈希的输入应用填充,然后将输入切成可以适应压缩函数的块。填充意味着向输入附加特定字节,以使其长度成为某个块大小的倍数。将填充后的输入切成相同块大小的块使我们能够将这些块放入压缩函数的第一个参数中。例如,SHA-256 的块大小为 512 位。图 2.9 说明了这一步骤。

图 2.9 默克尔-达姆高构造的第一步是向输入消息添加一些填充。此步骤完成后,输入长度应为所使用压缩函数的输入大小的倍数(例如,8 字节)。为此,我们在末尾添加 5 字节填充使其为 32 字节。然后,我们将消息分割成 4 个 8 字节的块。
其次,它迭代地将压缩函数应用于消息块,使用前一个压缩函数的输出作为压缩函数的第二个参数。最终输出是摘要。图 2.10 说明了这一步骤。

图 2.10 默克尔-达姆高构造迭代地对要散列的每个输入块和上一个压缩函数的输出应用压缩函数。对压缩函数的最终调用直接返回摘要。
这就是 SHA-2 的工作原理,通过迭代调用其压缩函数对输入的片段进行处理,直到全部处理为最终摘要。
注意,如果压缩函数本身是证明碰撞抵抗的,那么默克尔-达姆高构造就被证明是抗碰撞的。因此,任意长度输入的哈希函数的安全性降低到一个固定大小的压缩函数的安全性,这更容易设计和分析。这就是默克尔-达姆高构造的巧妙之处。
起初,压缩函数的第二个参数通常被固定和标准化为“无暗藏的”值。具体来说,SHA-256 使用第一个质数的平方根来导出这个值。无暗藏值的目的是让密码学界相信它不是为了使哈希函数更弱(例如,为了创建后门)而选择的。这是密码学中的一个流行概念。
警告:虽然 SHA-2 是一个完全可以使用的哈希函数,但不适合用于哈希秘密信息。这是因为 Merkle–Damgård 结构的一个缺点,使得 SHA-2 在处理秘密信息时容易受到攻击(称为长度扩展攻击)。我们将在下一章节中更详细地讨论这个问题。
2.5.2 SHA-3 哈希函数
正如我之前提到的,最近一段时间,MD5 和 SHA-1 哈希函数都被破解了。这两个函数都使用了我在前一节中描述的相同的 Merkle–Damgård 结构。因此,由于 SHA-2 容易受到长度扩展攻击的影响,NIST 于 2007 年决定组织一个新标准的公开竞赛:SHA-3。本节介绍了这个更新的标准,并试图对其内部工作原理进行高层次的解释。
2007 年,来自不同国际研究团队的 64 个不同候选者参加了 SHA-3 竞赛。五年后,其中一个提交的算法 Keccak 被提名为获胜者,并取名为 SHA-3。2015 年,SHA-3 被标准化为 FIPS 出版物 202(nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.202.pdf)。
SHA-3 遵循我们之前讨论的三个安全属性,并提供与 SHA-2 变种一样多的安全性。此外,它不容易受到长度扩展攻击,并且可以用于哈希秘密信息。因此,现在推荐使用它作为哈希函数。它提供与 SHA-2 相同的变种,这次在它们的命名变种中标明了全名 SHA-3:SHA-3-224、SHA-3-256、SHA-3-384 和 SHA-3-512。因此,类似于 SHA-2,例如,SHA-3-256 提供 256 位的输出。现在让我花几页的篇幅来解释 SHA-3 的工作原理。
SHA-3 是建立在置换之上的密码算法。理解置换的最简单方法是想象以下:你在左边有一组元素,在右边也有同样的一组元素。现在画箭头从左边的每个元素指向右边。每个元素只能有一个从它开始并结束的箭头。现在你有了一个置换。图 2.11 说明了这个原理。根据定义,任何置换也是可逆的,这意味着从输出我们可以找到输入。

图 2.11 一个作用在四种不同形状上的示例置换。您可以使用中间图片中描述的置换来转换给定的形状。
SHA-3 是建立在海绵构造上的,这是 SHA-3 竞赛中发明的一种不同于 Merkle–Damgård 的构造。它基于一个特定的置换称为keccak-f,它接受一个输入并返回相同大小的输出。
注意 我们不会解释 keccak-f 是如何设计的,但是你将在第四章中对此有一个概念,因为它与 AES 算法实质上是相似的(除了它没有密钥)。这不是偶然的,因为 AES 的发明者之一也是 SHA-3 的发明者之一。
在接下来的几页中,我将使用一个 8 位排列来说明海绵结构的工作原理。因为排列已经固定,你可以想象图 2.12 很好地说明了这个排列在所有可能的 8 位输入上创建的映射。与我们之前对排列的解释相比,你也可以想象每个可能的 8 位字符串是我们所代表的不同形状(000...是一个三角形,100...是一个正方形,等等)。

图 2.12 一个海绵结构利用了一个指定的排列 f。通过作用于输入,我们的示例排列创建了一个映射,将所有可能的 8 位输入和所有可能的 8 位输出联系起来。
要在我们的海绵结构中使用一个排列,我们还需要定义一个将输入和输出分成 速率 和 容量 的任意划分。这有点奇怪,但请坚持。图 2.13 说明了这个过程。

图 2.13 排列 f 将一个大小为 8 位的输入随机化为一个相同大小的输出。在海绵结构中,这个排列的输入和输出被分成两部分:速率(大小为 r)和容量(大小为 c)。
我们设置速率和容量之间的限制是任意的。不同版本的 SHA-3 使用不同的参数。我们非正式地指出容量应该像一个秘密一样对待,而且容量越大,海绵结构就越安全。
现在,像所有良好的哈希函数一样,我们需要能够哈希一些东西,对吧?否则,它有点没用。为了做到这一点,我们简单地将输入与排列的输入速率进行异或(⊕)。起初,这只是一堆 0。正如我们之前指出的,容量被视为一个秘密,所以我们不会与之进行任何异或运算。图 2.14 说明了这一点。

图 2.14 要吸收输入的 5 位 00101,一个速率为 5 位的海绵结构可以简单地将这 5 位与速率进行异或(其初始化为 0)。然后置换混淆状态。
现在获得的输出看起来应该是随机的(尽管我们可以轻松地找到输入,因为按照定义排列是可逆的)。如果我们想要输入更大的输入呢?嗯,类似于我们对 SHA-2 所做的,我们会
-
如果需要,填充输入,然后将输入分成速率大小的块。
-
迭代地调用排列,同时对每个块与排列的输入进行异或,并在每个块与排列的输入进行异或后对 状态(上次操作输出的中间值)进行排列。
为了简化起见,我在其余的解释中忽略了填充,但填充是区分诸如0和00之类的输入的重要步骤。图 2.15 展示了这两个步骤。

图 2.15 为了吸收比速率大小更大的输入,海绵构造会迭代地对输入块与速率进行异或运算,并对结果进行排列。
到目前为止一切顺利,但我们还没有生成摘要。为了做到这一点,我们可以简单地使用海绵的最后状态的速率(再次强调,我们不会触及容量)。要获得更长的摘要,我们可以继续对状态的速率部分进行排列和读取,正如图 2.16 所示。

图 2.16 为了使用海绵构造获取摘要,需要迭代地排列状态并检索尽可能多的速率(状态的上部)。
这就是 SHA-3 的工作原理。因为它是一个海绵构造,所以摄取输入自然被称为吸收,创建摘要被称为挤压。海绵采用一个 1,600 比特的置换,根据 SHA-3 不同版本广告的安全性,使用不同的r和c值进行规定。
SHA-3 是一个随机神谕
我之前提到过随机神谕:这是一个理想的虚构构造,对查询返回完全随机的响应,并且如果我们用相同的输入两次查询它,它会重复自己。事实证明,只要构造所使用的置换看起来足够随机,海绵构造的行为就会接近随机神谕。我们如何证明这种置换的安全性质?我们最好的方法是尝试多次破解它,直到我们对其设计有了强烈的信心(这就是 SHA-3 竞赛期间发生的情况)。SHA-3 可以被建模为随机神谕的事实立即赋予了它我们期望从哈希函数得到的安全属性。
2.5.3 SHAKE 和 cSHAKE:两个可扩展输出函数(XOF)
我介绍了两个主要的哈希函数标准:SHA-2 和 SHA-3。这些都是明确定义的哈希函数,可以接受任意长度的输入,并产生看起来随机而固定长度的输出。正如您将在后面的章节中看到的,加密协议经常需要这种类型的原语,但不希望受到哈希函数摘要的固定大小的限制。因此,SHA-3 标准引入了一个更具多功能性的原语,称为可扩展输出函数或XOF(发音为“zoff”)。本节介绍了两个标准化的 XOF:SHAKE 和 cSHAKE。
SHAKE,在 FIPS 202 中规定,可以看作是返回任意长度输出的哈希函数。SHAKE 基本上与 SHA-3 相同的构造,只是它更快,并在挤压阶段中可以排列任意数量的排列。生成不同大小的输出非常有用,不仅用于创建摘要,还用于创建随机数,派生密钥等。我将在本书中再次讨论 SHAKE 的不同应用;现在,想象一下 SHAKE 就像 SHA-3,只是它提供任何你想要的长度的输出。
这种构造在密码学中非常有用,以至于在 SHA-3 标准化一年后,NIST 发布了其特殊出版物 800-185,其中包含了一个称为cSHAKE的可定制 SHAKE。cSHAKE 与 SHAKE 几乎完全相同,只是它还接受一个自定义字符串。这个自定义字符串可以为空,也可以是任何您想要的字符串。让我们首先看一个在伪代码中使用 cSHAKE 的示例:
cSHAKE(input="hello world", output_length=256, custom_string="my_hash")
-> 72444fde79690f0cac19e866d7e6505c
cSHAKE(input="hello world", output_length=256, custom_string="your_hash")
-> 688a49e8c2a1e1ab4e78f887c1c73957
正如您所看到的,尽管 cSHAKE 与 SHAKE 和 SHA-3 一样确定性,但两个摘要不同。这是因为使用了不同的自定义字符串。自定义字符串允许您自定义您的 XOF!这在一些协议中非常有用,例如,必须使用不同的哈希函数才能使证明有效。我们称之为领域分离。
作为密码学中的黄金法则:如果相同的密码原语用于不同的用例,不要使用相同的密钥(如果需要密钥)和/或应用领域分离。在后续章节中,我们将在调查密码协议时看到更多领域分离的示例。
警告 NIST 倾向于指定以比特为单位而不是字节的参数算法。在示例中,请求了 256 比特的长度。想象一下,如果您请求了 16 字节的长度,却得到了 2 字节,因为程序认为您请求了 16 比特的输出。这个问题有时被称为比特攻击。
与密码学中的一切一样,像密钥、参数和输出这样的密码字符串的长度与系统的安全性密切相关。重要的是不要从 SHAKE 或 cSHAKE 请求太短的输出。使用 256 比特的输出永远不会错,因为它提供了 128 比特的安全性,可以抵御碰撞攻击。但是,现实世界的密码学有时在可能使用较短的密码值的受限环境中运行。如果系统的安全性经过仔细分析,可以这样做。例如,如果协议中不需要碰撞抵抗,只需要从 SHAKE 或 cSHAKE 获得 128 比特长的输出。
2.5.4 避免使用 TupleHash 进行模糊哈希
在本章中,我已经讨论了不同类型的密码原语和密码算法。这包括
-
SHA-2 哈希函数,容易受到长度扩展攻击的攻击,但在没有秘密被哈希时仍然广泛使用
-
SHA-3 哈希函数,现在是推荐使用的哈希函数
-
SHAKE 和 cSHAKE XOFs,比哈希函数更多变的工具,因为它们提供可变的输出长度
我将讨论另一个方便的函数,TupleHash,它基于 cSHAKE 并在与 cSHAKE 相同的标准中指定。TupleHash 是一个有趣的函数,它允许对元组(一些东西的列表)进行哈希。为了解释 TupleHash 是什么以及它为什么有用,让我给你讲个故事。
几年前,作为工作的一部分,我被委派审查一个加密货币。它包括一个加密货币应有的基本功能:账户、支付等。用户之间的交易将包含有关谁向谁发送多少的元数据。它还包括一笔小费用以补偿网络处理交易所需的成本。
例如,艾丽斯可以向网络发送交易,但要让它们被接受,她需要包含证明该交易来自她的证据。为此,她可以对交易进行哈希并签名(我在第一章中给出了一个类似的例子)。任何人都可以对交易进行哈希并验证哈希上的签名,以查看这是否是艾丽斯打算发送的交易。图 2.17 说明了一个中间人(MITM)攻击者在交易到达网络之前截取交易后,将无法篡改交易。这是因为哈希将会改变,然后签名将不会验证新的交易摘要。

图 2.17 艾丽斯发送一个交易以及对交易哈希的签名。如果中间人攻击者试图篡改交易,哈希将会不同,因此附加的签名也将不正确。
你将在第七章看到,这样的攻击者当然无法伪造艾丽斯在新摘要上的签名。并且由于所使用的哈希函数的第二预像抗性,攻击者也无法找到一个完全不同的交易,其哈希为相同的摘要。
我们的中间人攻击者无害吗?我们还没有脱离危险。不幸的是,对于我审计的加密货币,交易是通过简单地串联每个字段进行哈希的:
$ echo -n "Alice""Bob""100""15" | openssl dgst -sha3-256
34d6b397c7f2e8a303fc8e39d283771c0397dad74cef08376e27483efc29bb02
表面上看似乎一切正常,实际上完全破坏了加密货币的支付系统。这样做很容易使攻击者打破哈希函数的第二预像抗性。花点时间思考一下你如何找到一个不同的交易,其哈希为34d6...。
如果我们将一个数字从fee字段移到amount字段会发生什么?人们可以看到以下交易哈希到了同样的摘要,艾丽斯签署了:
$ echo -n "Alice""Bob""1001""5" | openssl dgst -sha3-256
34d6b397c7f2e8a303fc8e39d283771c0397dad74cef08376e27483efc29bb02
因此,一个想让鲍勃获得更多钱的中间人攻击者可以修改交易而不使签名无效。正如您可能已经猜到的那样,这就是 TupleHash 解决的问题。它允许您通过使用非模糊编码来明确地对字段列表进行哈希处理。实际上发生的情况与以下内容类似(使用||字符串连接操作):
cSHAKE(input="5"||"Alice"||"3"||"Bob"||"3"||"100"||"2"||"10",
➥ output_length=256, custom_string="TupleHash"+"anything you want")
这次输入是通过在交易的每个字段前加上其长度来构造的。花点时间理解为什么这样解决了我们的问题。一般来说,通过在对其进行哈希处理之前始终确保序列化输入,可以安全地使用任何哈希函数。序列化输入意味着始终存在一种方法来反序列化它(即恢复原始输入)。如果可以反序列化数据,则字段分隔就不会存在任何歧义。
2.6 密码哈希
在本章中,您已经看到了几个有用的函数,这些函数要么是哈希函数,要么是扩展哈希函数。但在您跳转到下一章之前,我需要提到密码哈希。
想象一下以下情景:您有一个网站(这将使您成为网站管理员),您希望用户注册并登录到该网站,因此您为这两个功能分别创建了两个网页。突然间,您想知道,您将如何存储他们的密码?您在数据库中以明文存储这些密码吗?起初似乎没有什么问题,您认为。但这并不完美。人们倾向于在各处重复使用相同的密码,如果(或者当)您遭受攻击并且攻击者设法倾倒所有用户的密码,这对您的用户来说将是不好的,对您的平台声誉也将是不好的。您再仔细考虑一下,您意识到一个攻击者如果能够窃取这个数据库,那么他将能够以任何用户的身份登录。以明文存储密码现在不再理想,您希望有更好的处理方式。
一种解决方案可能是对密码进行哈希处理,然后仅存储摘要。当有人登录到您的网站时,流程将类似于以下内容:
-
您收到用户的密码。
-
您对用户提供的密码进行哈希处理并丢弃密码。
-
您将摘要与先前存储的内容进行比较;如果匹配,则用户已登录。
该流程允许您在有限时间内处理用户的密码。但是,一旦攻击者进入您的服务器,就可以悄悄地保留从该流程中记录密码,直到您察觉到其存在。我们承认这仍然不是一个完美的情况,但我们仍然改进了网站的安全性。在安全领域,我们也称之为深度防御,即通过分层不完美的防御措施,希望攻击者无法击败所有这些层次。这也是现实世界的加密学所涉及的内容。但是,这种解决方案还存在其他问题:
-
如果攻击者获取了哈希密码,可以进行暴力破解攻击或穷举搜索(尝试所有可能的密码)。 这将针对整个数据库测试每个尝试。理想情况下,我们希望攻击者只能一次攻击一个哈希密码。
-
哈希函数应该尽可能快。 攻击者可以利用这一点进行暴力破解(每秒尝试许多密码)。理想情况下,我们应该有一种机制来减慢这种攻击。
第一个问题通常通过使用 盐 解决,盐是公开的随机值,每个用户都不同。当我们对用户的密码进行哈希处理时,我们使用一个盐,这在某种程度上类似于在 cSHAKE 中使用每个用户的自定义字符串:它实际上为每个用户创建了一个不同的哈希函数。由于每个用户使用不同的哈希函数,攻击者无法预先计算大量密码(称为 彩虹表),希望将其与窃取的密码哈希数据库整个测试相匹配。
第二个问题通过 密码哈希 解决,这些密码哈希设计为缓慢。目前用于此的最先进选择是 Argon2,它是从 2013 年到 2015 年举办的密码哈希竞赛 (password-hashing.net) 的获胜者。本文撰写时(2021 年),Argon2 正在按计划标准化为 RFC (datatracker.ietf.org/doc/draft-irtf-cfrg-argon2/)。在实践中,还使用其他非标准算法,如 PBKDF2、bcrypt 和 scrypt。问题在于这些算法可能使用不安全的参数,并且因此在实践中配置起来并不简单。
此外,只有 Argon2 和 scrypt 能够抵御来自攻击者的重度优化,因为其他方案不是内存硬化的。术语 内存硬化 意味着算法只能通过内存访问的优化来进行优化。换句话说,优化其余部分并不会带来太大好处。由于即使使用专用硬件(CPU 周围只能放置那么多缓存),内存硬化函数在任何类型的设备上运行速度都很慢。当你想要防止攻击者在评估函数时获得非可忽略的速度优势时,这是一种期望的属性。
图 2.18 回顾了本章中你所看到的不同类型的哈希函数。

图 2.18 在本章中,你看到了四种类型的哈希函数:(1) 普通类型的哈希函数为任意长度的输入提供了一个唯一的随机标识符;(2) 可扩展输出函数与普通类型类似,但提供了任意长度的输出;(3) 元组哈希函数清楚地列出了哈希值;以及 (4) 无法轻易优化以安全存储密码的密码哈希函数。
摘要
-
哈希函数提供碰撞抗性、前像抗性和第二前像抗性。
-
前像抗性意味着不应该能够找到产生摘要的输入。
-
第二前像抗性意味着从一个输入及其摘要出发,不应该能够找到一个产生相同摘要的不同输入。
-
碰撞抗性意味着不应该能够找到两个随机输入,它们的哈希值相同。
-
-
最广泛采用的哈希函数是 SHA-2,而推荐的哈希函数是 SHA-3,因为 SHA-2 缺乏对长度扩展攻击的抵抗力。
-
SHAKE 是一种可扩展输出函数(XOF),它的行为类似于哈希函数,但提供任意长度的摘要。
-
cSHAKE(用于定制 SHAKE)允许轻松创建行为像不同 XOF 的 SHAKE 实例。这被称为域分离。
-
对象在进行哈希处理之前应进行序列化,以避免破坏哈希函数的第二前像抗性。像 TupleHash 这样的算法会自动处理这一点。
-
对密码进行哈希处理时使用的是专门设计用于此目的的较慢的哈希函数。Argon2 是最先进的选择。
第三章:消息认证码
本章涵盖
-
消息认证码(MACs)
-
MAC 的安全性属性和陷阱
-
广泛采用的 MAC 标准
将哈希函数与秘密密钥混合在一起,你就得到了一种称为消息认证码(MAC)的东西,它是一种用于保护数据完整性的密码原语。添加秘密密钥是任何类型安全的基础:没有密钥就没有机密性,也没有认证。虽然哈希函数可以为任意数据提供认证或完整性,但这要归功于一个不可篡改的额外受信任的通道。在本章中,你将看到 MAC 如何用于创建这样一个受信任的通道,以及它还能做些什么。
注意 对于本章,您需要已阅读了第二章的哈希函数。
无状态 cookies,MAC 的一个激励示例
假设下面的场景:你是一个网页。你色彩明亮,充满活力,最重要的是,你以为一群忠实用户提供服务感到自豪。要与你互动,访客必须首先通过发送他们的凭据来登录,然后你必须验证这些凭据。如果凭据与用户首次注册时使用的凭据匹配,那么你已成功验证了用户。
当然,Web 浏览体验不仅仅是一个请求,而是多个请求的组合。为了避免用户在每个请求中重新进行身份验证,你可以让他们的浏览器存储用户凭据,并在每个请求中自动重新发送。浏览器就有一个专门的功能——cookies! Cookies 不仅仅用于凭据。它们可以存储任何你希望用户在每个请求中发送给你的内容。
尽管这种天真的方法效果很好,但通常你不希望在浏览器中以明文形式存储诸如用户密码之类的敏感信息。相反,会话 cookie 最常携带一个随机字符串,在用户登录后立即生成。Web 服务器将随机字符串存储在临时数据库中,使用用户的昵称作为标识。如果浏览器以某种方式发布了会话 cookie,就不会泄露有关用户密码的任何信息(尽管可以使用它来冒充用户)。Web 服务器还有可能通过在其端删除 cookie 来终止会话,这很好。

这种方法没有问题,但在某些情况下,它可能不太适合扩展。如果你有许多服务器,让所有服务器共享用户和随机字符串之间的关联可能会很麻烦。相反,你可以在浏览器端存储更多信息。让我们看看如何做到这一点。
天真地,你可以让 cookie 包含一个用户名而不是一个随机字符串,但这显然是一个问题,因为我现在可以通过手动修改 cookie 中包含的用户名来冒充任何用户。也许你在第二章学到的哈希函数能帮助我们。花几分钟想想哈希函数如何防止用户篡改自己的 cookie。
第二种天真的方法可能是不仅在 cookie 中存储一个用户名,还存储该用户名的摘要。你可以使用像 SHA-3 这样的哈希函数来对用户名进行哈希。我在图 3.1 中说明了这一点。你认为这个方法可行吗?

图 3.1 为了验证浏览器的请求,web 服务器要求浏览器存储一个用户名和该用户名的哈希,并在每个后续请求中发送这些信息。
这种方法有一个很大的问题。请记住,哈希函数是一个公开的算法,恶意用户可以重新计算新数据上的哈希。如果你不信任哈希的来源,它就无法提供数据完整性!的确,图 3.2 显示,如果恶意用户修改了其 cookie 中的用户名,他们也可以简单地重新计算 cookie 的摘要部分。

图 3.2 恶意用户可以修改其 cookie 中包含的信息。如果一个 cookie 包含一个用户名和一个哈希,两者都可以被修改以冒充不同的用户。
使用哈希仍然不是一个愚蠢的想法。我们还能做什么?事实证明,有一种与哈希函数类似的原始方法,叫做 MAC,它正好可以满足我们的需求。
MAC是一个秘密密钥算法,它像哈希函数一样接受一个输入,但它还接受一个秘密密钥(谁会想到呢?)然后产生一个称为认证标签的唯一输出。这个过程是确定性的;给定相同的秘密密钥和相同的消息,MAC 会产生相同的认证标签。我在图 3.3 中说明了这一点。

图 3.3 一个消息认证码(MAC)的接口。该算法接受一个秘密密钥和一个消息,并确定性地生成一个唯一的认证标签。没有密钥的话,应该无法再现那个认证标签。
为了确保用户无法篡改他们的 cookie,让我们现在利用这种新的原始方法。当用户第一次登录时,你使用你的秘密密钥和他们的用户名生成一个认证标签,并要求他们将他们的用户名和认证标签存储在cookie中。因为他们不知道秘密密钥,所以他们将无法伪造出不同用户名的有效认证标签。
要验证他们的 cookie,你做同样的事情:使用你的秘密密钥和 cookie 中包含的用户名生成一个身份验证标签,并检查它是否与 cookie 中包含的身份验证标签匹配。如果匹配,那么它必定来自你,因为只有你能够生成有效的身份验证标签(在你的秘密密钥下)。我在图 3.4 中说明了这一点。

图 3.4 一个恶意用户篡改了他的 cookie,但无法伪造新 cookie 的有效身份验证标签。随后,网页无法验证 cookie 的真实性和完整性,因此丢弃了请求。
MAC 就像一个私有的哈希函数,只有你知道密钥才能计算出来。在某种意义上,你可以用密钥个性化一个哈希函数。与哈希函数的关系并不止于此。你将在本章后面看到,MAC 经常是从哈希函数构建的。接下来,让我们看一个使用真实代码的不同示例。
3.2 一个代码示例
到目前为止,只有你在使用 MAC。让我们增加参与者的数量,并以此为动机编写一些代码,看看 MAC 在实践中是如何使用的。想象一下,你想与其他人通信,而不在乎其他人是否阅读你的消息。但你真正关心的是消息的完整性:它们不能被修改!一个解决方案是你和你的通信对象使用相同的秘密密钥和 MAC 来保护通信的完整性。
对于这个示例,我们将使用最流行的 MAC 函数之一——基于哈希的消息认证码(HMAC)与 Rust 编程语言一起使用。HMAC 是一种使用哈希函数作为核心的消息认证码。它与不同的哈希函数兼容,但主要与 SHA-2 一起使用。如下列表所示,发送部分只需接受一个密钥和一个消息,然后返回一个身份验证标签。
列表 3.1 在 Rust 中发送经过身份验证的消息
use sha2::Sha256;
use hmac::{Hmac, Mac, NewMac};
fn send_message(key: &[u8], message: &[u8]) -> Vec<u8> {
let mut mac = Hmac::<Sha256>::new(key.into()); // ❶
mac.update(message); // ❷
mac.finalize().into_bytes().to_vec() // ❸
}
❶ 使用秘密密钥和 SHA-256 哈希函数实例化 HMAC
❷ 为 HMAC 缓冲更多输入
❸ 返回身份验证标签
另一方面,流程类似。在接收到消息和身份验证标签后,你的朋友可以使用相同的秘密密钥生成自己的标签,然后进行比较。与加密类似,双方需要共享相同的秘密密钥才能使其正常工作。以下列表显示了这是如何工作的。
列表 3.2 在 Rust 中接收经过身份验证的消息
use sha2::Sha256;
use hmac::{Hmac, Mac, NewMac};
fn receive_message(key: &[u8], message: &[u8],
authentication_tag: &[u8]) -> bool {
let mut mac = Hmac::<Sha256>::new(key); // ❶
mac.update(message); // ❷
mac.verify(&authentication_tag).is_ok()
}
❶ 接收方需要从相同的密钥和消息中重新创建身份验证标签。
❷ 检查重现的身份验证标签是否与接收到的标签匹配
注意,这个协议并不完美:它允许重放攻击。如果一个消息及其认证标签在以后的某个时间点被重放,它们仍然是真实的,但你将无法检测到它是一条旧消息被重新发送给你。本章后面,我会告诉你一个解决方案。现在你知道了 MAC 可以用来做什么,我会在下一节谈谈 MAC 的一些“坑”。
3.3 MAC 的安全属性
MACs,像所有的密码学原语一样,有它们的怪异之处和陷阱。在继续之前,我将对 MAC 提供的安全属性以及如何正确使用它们提供一些解释。你会依次学到(按顺序):
-
MACs 抵抗认证标签的伪造。
-
一个认证标签需要有足够的长度才能保证安全。
-
如果简单地进行认证,消息可以被重放。
-
验证认证标签容易出现错误。
3.3.1 认证标签伪造
一个 MAC 的一般安全目标是防止在新消息上伪造认证标签。这意味着在不知道秘钥 k 的情况下,无法计算出认证标签 t = MAC(k, m) 在用户选择的消息 m 上。这听起来合理,对吧?如果我们缺少一个参数,我们就不能计算出一个函数。
然而,MACs 提供了比这更多的保证。现实世界的应用程序通常会让攻击者获取一些受限制的消息的认证标签。例如,在我们的介绍场景中,这就是问题所在,用户可以通过注册一个可用的昵称来获得几乎任意的认证标签。因此,MACs 必须甚至对这些更强大的攻击者也是安全的。一个 MAC 通常附带一个证明,即使攻击者可以要求你为大量的任意消息产生认证标签,攻击者也不能自己伪造一个以前从未见过的消息的认证标签。
注意有人可能会想知道证明这样一个极端性质的用处是什么。如果攻击者可以直接请求任意消息的认证标签,那么还剩下什么需要保护的呢?但这就是密码学中安全证明的工作原理:它们考虑到最强大的攻击者,甚至在那种情况下,攻击者也是无能为力的。在实践中,攻击者通常不那么强大,因此,我们相信如果一个强大的攻击者无法做出恶意行为,一个不那么强大的攻击者就更加无能为力了。
因此,只要与 MAC 一起使用的秘钥保持秘密,你就应该受到保护。这意味着秘钥必须足够随机(在第八章中详细讨论)和足够大(通常为 16 字节)。此外,一个 MAC 对于我们在第二章中看到的相同类型的模糊攻击也是脆弱的。如果你试图验证结构,请确保在用 MAC 验证之前将它们序列化;否则,伪造可能是微不足道的。
3.3.2 认证标签的长度
针对 MAC 的另一个可能攻击是碰撞。记住,找到哈希函数的碰撞意味着找到两个不同的输入 X 和 Y,使得 HASH(X) = HASH(Y)。我们可以通过定义当 MAC(k, X) = MAC(k, Y) 时输入 X 和 Y 发生碰撞来将此定义扩展到 MAC。
正如我们在第二章学到的生日攻击边界一样,如果我们算法的输出长度较小,则可以高概率地找到碰撞。例如,对于 MAC,如果攻击者可以访问生成 64 位认证标签的服务,则可以通过请求较少的标签数(232)高概率地找到碰撞。在实践中,这样的碰撞很少能够被利用,但存在一些碰撞抗性很重要的情况。因此,我们希望认证标签大小能够限制此类攻击。一般来说,使用 128 位认证标签是因为它们提供足够的抗性。
[请求 2⁶⁴ 个认证标签] 在连续 1Gbps 链路上需要 250,000 年,并且在此期间不更改秘密密钥 K。
—RFC 2104(“HMAC:用于消息认证的键控哈希”,1997)
使用 128 位认证标签可能看起来有些反直觉,因为我们希望哈希函数的输出为 256 位。但是哈希函数是公开算法,攻击者可以离线计算,这使得攻击者能够对攻击进行优化和并行化。使用像 MAC 这样的密钥函数,攻击者无法有效地离线优化攻击,而是被迫直接向您请求认证标签,这通常会使攻击速度变慢。128 位认证标签需要攻击者在线查询 2⁶⁴ 次,才有 50% 的机会找到碰撞,这被认为足够大。尽管如此,某些情况下可能仍希望将认证标签增加到 256 位,这也是可能的。
3.3.3 重播攻击
我还没提到的一件事是重播攻击。让我们看一个容易受到此类攻击的场景。假设 Alice 和 Bob 使用不安全的连接在公开场合进行通信。为了防止消息篡改,他们在每条消息后附上认证标签。更具体地说,他们都使用两个不同的秘密密钥来保护连接的不同侧面(按最佳实践)。我在图 3.5 中说明了这一点。

图 3.5 两个用户共享两个密钥 k1 和 k2,并随消息一起交换认证标签。这些标签是根据消息的方向从 k1 或 k2 计算出来的。恶意观察者会重播其中一条消息给用户。
在这种情况下,没有任何东西能阻止恶意观察者向其接收者重播其中一条消息。依赖于 MAC 的协议必须意识到这一点,并构建对抗措施。一种方法是像图 3.6 中所示,向 MAC 的输入添加一个递增计数器。

图 3.6 两个用户共享两个密钥 k1 和 k2,并与身份验证标签一起交换消息。这些标签是根据消息的方向从 k1 或 k2 计算的。恶意观察者向用户重播其中一个消息。因为受害者已经增加了他的计数器,标签将被计算为 2, fine and you?,并且不会与攻击者发送的标签匹配。这使得受害者能够成功拒绝重放的消息。
在实践中,计数器通常是固定的 64 位长度。这允许在填满计数器之前发送 2⁶⁴ 条消息(并且有风险包装和重复自身)。当然,如果共享的密钥经常旋转(意味着在X条消息后,参与者同意使用新的共享密钥),那么计数器的大小可以缩小,并且在密钥旋转后重置为 0。(你应该确信重复使用相同的计数器与两个不同的密钥是可以的。)再次强调,由于存在歧义攻击,计数器永远不是可变长度的。
练习
你能想象出一个可变长度计数器如何可能允许攻击者伪造身份验证标签吗?
3.3.4 在恒定时间内验证身份验证标签
最后一个注意事项对我来说很重要,因为我在审计的应用程序中多次发现了这个漏洞。在验证身份验证标签时,接收到的身份验证标签和你计算的标签之间的比较必须在恒定时间内完成。这意味着比较应该始终花费相同的时间,假设接收到的标签是正确大小的。如果比较两个身份验证标签所花费的时间不是恒定时间,那么很可能是因为它在两个标签不同时返回。这通常提供了足够的信息,以启用通过测量验证完成所需时间来逐字节重新创建有效身份验证标签的攻击。我在以下漫画中解释了这一点。我们将这类攻击称为时序攻击。
幸运的是,实现 MAC 的加密库还提供了方便的函数,以恒定的时间验证身份验证标签。如果你想知道这是如何做到的,清单 3.3 展示了 Golang 如何在恒定时间代码中实现身份验证标签比较。

清单 3.3 Golang 中的常量时间比较
for i := 0; i < len(x); i++ {
v |= x[i] ^ y[i]
}
窍门在于从不采取任何分支。具体工作原理留给读者作为练习。
3.4 现实世界中的 MAC
现在我已经介绍了 MAC 是什么以及它们提供的安全属性,让我们看看人们在实际环境中如何使用它们。以下章节将讨论这一点。
3.4.1 消息认证
MACs 被广泛用于确保两台机器或两个用户之间的通信不被篡改。这在通信以明文传输和通信以加密方式传输的情况下都是必要的。我已经解释了当通信以明文传输时会发生什么,而在第四章中,我将解释在通信加密时如何实现这一点。
3.4.2 密钥派生
MACs 的一个特点是它们通常被设计为生成看起来随机的字节(就像哈希函数)。您可以利用这个特性实现一个单一的密钥来生成随机数,或者生成更多的密钥。在第八章关于秘密和随机性中,我将介绍基于 HMAC 的密钥派生函数(HKDF),它通过使用 HMAC 来实现这一点,HMAC 是我们将在本章中讨论的 MAC 算法之一。
伪随机函数(PRF)
想象一下,所有接受可变长度输入并生成固定大小随机输出的函数的集合。如果我们可以从这个集合中随机选择一个函数并将其用作 MAC(没有密钥),那就太好了。我们只需就选择哪个函数达成一致(有点像达成一致选择密钥)。不幸的是,我们不能拥有这样的集合,因为它太大了,但我们可以通过设计一些接近的东西来模拟选择这样一个随机函数:我们称这样的构造为伪随机函数(PRFs)。HMAC 和大多数实用的 MAC 都是这样的构造。它们通过一个密钥参数进行随机化。选择不同的密钥就像选择一个随机函数。
练习
注意:并非所有的 MAC 都是 PRF。你能看出为什么吗?
3.4.3 Cookie 的完整性
要追踪用户的浏览器会话,您可以向他们发送一个随机字符串(与他们的元数据相关联)或直接发送元数据,附带身份验证标签,以便他们无法修改它。这就是我在引言例子中解释的内容。
3.4.4 哈希表
编程语言通常公开称为哈希表(也称为哈希映射、字典、关联数组等)的数据结构,这些数据结构使用非密码散列函数。如果一个服务以这样一种方式公开此数据结构,使得攻击者可以控制非密码散列函数的输入,这可能导致拒绝服务(DoS)攻击,意味着攻击者可以使服务无法使用。为了避免这种情况,非密码散列函数通常在程序启动时进行随机化。
许多主要的应用程序使用一个随机密钥的 MAC 代替非密码散列函数。这适用于许多编程语言(如 Rust、Python 和 Ruby)或主要应用程序(如 Linux 内核)。它们都使用SipHash,一个针对短身份验证标签进行优化的 MAC,该标签在程序启动时生成随机密钥。
3.5 实践中的消息认证码(MACs)
你已经了解到 MAC 是一种加密算法,可以在一个或多个参与方之间使用,以保护信息的完整性和真实性。由于广泛使用的 MAC 也表现出良好的随机性,MAC 也经常被用于在不同类型的算法中确定性地产生随机数(例如,你将在第十一章学习的基于时间的一次性密码[TOTP]算法)。在本节中,我们将介绍两种现在可以使用的标准化的 MAC 算法——HMAC 和 KMAC。
3.5.1 HMAC,一种基于哈希的 MAC
最广泛使用的 MAC 是 HMAC(基于哈希的 MAC),由 M. Bellare、R. Canetti 和 H. Krawczyk 于 1996 年发明,并在 RFC 2104、FIPS 出版物 198 和 ANSI X9.71 中指定。HMAC,正如其名称所示,是一种使用哈希函数和密钥的方法。使用哈希函数构建 MAC 的概念是一个流行的概念,因为哈希函数有广泛可用的实现,在软件中速度快,并且在大多数系统上也受到硬件支持。记得我在第二章提到过,由于长度扩展攻击(本章末尾将详细介绍),SHA-2 不应直接用于对秘密进行哈希处理。那么如何将哈希函数转换为带密钥的函数呢?这就是 HMAC 为我们解决的问题。在幕后,HMAC 遵循以下步骤,我在图 3.7 中通过可视化方式说明:
-
它首先从主密钥中创建两个密钥:k1 = k ⊕ ipad 和 k2 = k ⊕ opad,其中ipad(内部填充)和opad(外部填充)是常数, ⊕ 是异或操作的符号。
-
然后将一个密钥
k1与消息进行串联并对其进行哈希运算。 -
结果与一个密钥
k2进行串联,并再进行一次哈希运算。 -
这产生了最终的认证标签。

图 3.7 HMAC 通过对一个密钥k1和输入消息的串联(||)进行哈希运算,然后再对第一次操作的输出与另一个密钥k2的串联进行哈希运算来工作。k1和k2都是从一个秘密密钥k派生出来的确定性密钥。
由于 HMAC 是可定制的,其认证标签的大小取决于所使用的哈希函数。例如,HMAC-SHA256 使用 SHA-256 并产生 256 位的认证标签,HMAC-SHA512 产生 512 位的认证标签,依此类推。
警告虽然可以截断 HMAC 的输出以减小其大小,但认证标签应至少为 128 位,正如我们之前讨论的那样。这并不总是得到尊重,一些应用会降低到 64 位,因为明确处理了有限数量的查询。这种方法存在权衡,再次强调,在执行非标准操作之前,仔细阅读细则是很重要的。
HMAC 是这样构建的,以方便证明。在几篇论文中,已经证明 HMAC 在底层哈希函数具有一些良好属性时是安全的,而所有的密码学安全哈希函数都应该具备这些属性。由于这一点,我们可以将 HMAC 与大量的哈希函数结合使用。今天,HMAC 主要与 SHA-2 一起使用。
3.5.2 KMAC,基于 cSHAKE 的 MAC
由于 SHA-3 不容易受到长度扩展攻击的影响(这实际上是 SHA-3 竞赛的要求之一),在实践中使用 SHA-3 与 HMAC 相比,使用像SHA-3-256(key || message)这样的方法更合理。这正是KMAC所做的。
KMAC 利用了 cSHAKE,即您在第二章中看到的可定制版本的 SHAKE 可扩展输出函数(XOF)。KMAC 以一种明确的方式对 MAC 密钥、输入和请求的输出长度进行编码(KMAC 是一种可扩展输出 MAC),并将其作为 cSHAKE 的输入来吸收(参见图 3.8)。KMAC 还使用“KMAC”作为函数名称(以定制 cSHAKE),并且还可以接受用户定义的定制字符串。

图 3.8 KMAC 只是 cSHAKE 的一个包装器。为了使用密钥,它对密钥、输入和输出长度进行编码(以一种明确的方式),然后将其作为 cSHAKE 的输入。
有趣的是,由于 KMAC 还吸收了请求的输出长度,使用不同输出长度进行多次调用会得到完全不同的结果,这在一般情况下很少见于 XOFs。这使得 KMAC 在实践中成为一种非常多功能的函数。
3.6 SHA-2 和长度扩展攻击
我们已经多次提到,不应该使用 SHA-2 来哈希秘密,因为它对长度扩展攻击不具有抵抗力。在本节中,我们旨在对这种攻击进行简单解释。
让我们回到我们的引言情景,回到我们尝试简单地使用 SHA-2 来保护 cookie 的完整性的步骤。请记住,这还不够好,因为用户可以篡改 cookie(例如,添加一个admin=true字段)并重新计算 cookie 的哈希。确实,SHA-2 是一个公共函数,没有任何东西阻止用户这样做。图 3.9 说明了这一点。

图 3.9 一个网页发送一个 cookie,然后跟随着该 cookie 的哈希给一个用户。然后,要求用户在每次后续请求中发送 cookie 以验证自己。不幸的是,一个恶意用户可以篡改 cookie 并重新计算哈希,从而破坏完整性检查。然后网页接受该 cookie 为有效。
接下来最好的想法是在我们哈希的内容中添加一个秘钥。这样,用户无法重新计算摘要,因为需要秘钥,就像 MAC 一样。在接收到篡改的 cookie 时,页面计算SHA-256(key || tampered_cookie),其中||表示两个值的连接,并得到一个与恶意用户可能发送的内容不匹配的结果。图 3.10 说明了这种方法。

图 3.10 通过在计算 cookie 的哈希时使用一个秘钥,人们可能会认为想要篡改自己的 cookie 的恶意用户无法计算出新 cookie 的正确摘要。我们将在后面看到,对于 SHA-256 来说这并不成立。
不幸的是,SHA-2 有一个令人讨厌的特点:从一个输入的摘要中,可以计算出输入的摘要以及更多内容。这是什么意思呢?让我们看看图 3.11,其中使用 SHA-256 作为SHA-256(secret || input1)。

图 3.11 SHA-256 对一个与 cookie(这里命名为input1)连接的秘密进行哈希。请记住,SHA-256 通过使用 Merkle–Damgård 构造来迭代地调用压缩函数对输入的块进行处理,从初始化向量(IV)开始。
图 3.11 非常简化,但想象一下input1是字符串user=bob。请注意,获得的摘要实际上是哈希函数在这一点的完整中间状态。没有什么可以阻止假装填充部分是输入的一部分,继续 Merkle–Damgård 舞蹈。在图 3.12 中,我们说明了这种攻击,其中一个人会取得摘要并计算input1 || padding || input2的哈希。在我们的例子中,input2是&admin=true。

图 3.12 SHA-256 对 cookie 的哈希输出(中间摘要)用于扩展哈希到更多数据,创建一个哈希(右侧摘要),其中包括秘密与input1、第一个填充字节和input2的连接。
这个漏洞允许从给定的摘要继续哈希,就好像操作还没有完成一样。这打破了我们先前的协议,正如图 3.13 所示。

图 3.13 攻击者成功使用长度扩展攻击篡改他们的 cookie,并使用先前的哈希计算出正确的哈希。
现在第一个填充需要成为输入的一部分,这可能会阻止一些协议被利用。但是,最小的更改可能会重新引入漏洞。因此,永远不要使用 SHA-2 对秘密信息进行哈希。当然,还有几种正确的方法(例如,SHA-256(k || message || k)),这就是 HMAC 提供的功能。因此,如果要使用 SHA-2,请使用 HMAC,如果更喜欢 SHA-3,请使用 KMAC。
总结
-
消息验证码(MACs)是对称加密算法,允许共享相同密钥的一个或多个参与方验证消息的完整性和真实性。
-
要验证消息及其相关的认证标签的真实性,可以重新计算消息和一个秘密密钥的认证标签,然后比较这两个认证标签。如果它们不同,则消息已被篡改。
-
总是在恒定时间内将接收到的认证标签与计算得到的标签进行比较。
-
-
虽然消息验证码默认保护消息的完整性,但它们不能检测到消息被重播的情况。
-
标准化和广受认可的消息验证码包括 HMAC 和 KMAC 标准。
-
可以使用不同的哈希函数来进行 HMAC。实际上,HMAC 常与 SHA-2 哈希函数一起使用。
-
认证标签的最小长度应为 128 位,以防止认证标签的碰撞和伪造。
-
永远不要直接使用 SHA-256 来构建消息验证码,因为可能会出错。始终使用像 HMAC 这样的函数来完成这个任务。
第四章:认证加密
本章涵盖
-
对称加密与认证加密的区别
-
流行的认证加密算法
-
其他类型的对称加密
保密性是关于隐藏数据不被未经授权的人看到,而加密是实现这一目标的方法。加密是密码学最初被发明的目的;它是早期密码学家最关心的问题。他们会问自己,“我们如何防止观察者理解我们的对话?”虽然最初科学及其进展是在闭门之后蓬勃发展的,只有政府和军队受益,但现在已经向全世界开放。今天,加密在现代生活的各个方面被广泛使用以增加隐私和安全性。在本章中,我们将了解加密的真正含义,它解决了哪些问题,以及当今的应用程序如何大量使用这种密码原语。
注意 对于本章,您需要已经阅读了第三章关于消息认证码的内容。
4.1 什么是密码?
就像当你用俚语与兄弟姐妹谈论放学后要做什么,这样你的妈妈就不知道你在干什么。
—Natanael L. (2020, twitter.com/Natanael_L)
让我们想象一下我们的两个角色,爱丽丝和鲍勃,想要私下交换一些消息。在实践中,他们有许多可供选择的媒介(邮件、电话、互联网等),每个媒介默认都是不安全的。邮递员可能会打开他们的信件;电信运营商可以窥探他们的通话和短信;互联网服务提供商或者在爱丽丝和鲍勃之间的网络中的任何服务器都可以访问正在交换的数据包的内容。
不再拖延,让我们介绍一下爱丽丝和鲍勃的救星:加密算法(也称为密码)。现在,让我们把这个新算法想象成爱丽丝可以用来加密她发送给鲍勃的消息的黑匣子。通过对消息进行加密,爱丽丝将其转换为看起来随机的内容。这个加密算法需要
-
一个秘钥—这个元素的不可预测性、随机性和良好的保护至关重要,因为加密算法的安全性直接依赖于密钥的保密性。我将在第八章关于秘密和随机性中更多地讨论这一点。
-
一些明文—这是你想要加密的内容。它可以是一些文本、一张图片、一个视频,或者任何可以转换为比特的东西。
这个加密过程产生了一个密文,即加密后的内容。爱丽丝可以安全地使用之前列出的媒介之一将该密文发送给鲍勃。对于不知道秘钥的任何人来说,密文看起来是随机的,消息内容(明文)的任何信息都不会泄露。一旦鲍勃收到这个密文,他可以使用一个解密算法将密文恢复为原始明文。解密需要
-
一个秘密密钥 — 这是艾丽丝用于创建密文的相同秘密密钥。因为同一密钥用于两种算法,所以我们有时将密钥称为对称密钥。这也是为什么我们有时指定我们使用对称加密而不仅仅是加密。
-
一些密文 — 这是鲍勃从艾丽丝那里收到的加密消息。
然后该过程显示出原始明文。图 4.1 说明了此流程。

图 4.1 艾丽丝(右上)用密钥 0x8866...(一个缩写的十六进制数)加密明文 hello,然后将密文发送给鲍勃。鲍勃(右下)使用相同的密钥和解密算法解密收到的密文。
加密允许艾丽丝将她的消息转换成看起来随机的内容,并可以安全地传输给鲍勃。解密允许鲍勃将加密消息还原为原始消息。这种新的加密原语为他们的消息提供了保密性(或秘密性或隐私性)。
注意 艾丽丝和鲍勃如何同意使用相同的对称密钥?现在,我们假设其中一个人有权访问一个生成不可预测密钥的算法,并且他们亲自见面交换密钥。实际上,如何用共享的秘密来启动这样的协议通常是公司需要解决的重大挑战之一。在本书中,您将看到许多解决这个问题的不同方法。
请注意,我尚未介绍本章标题“认证加密”指的是什么。到目前为止,我只谈到了单独的加密。虽然单独的加密并不安全(稍后再说),但我必须先解释它是如何工作的,然后才能介绍认证加密原语。所以请容我先讲解加密的主要标准:高级加密标准(AES)。
4.2 高级加密标准(AES)块密码
1997 年,NIST 启动了一个旨在取代数据加密标准(DES)算法的高级加密标准(AES)的公开竞赛,他们以前的加密标准开始显露老化迹象。竞赛持续了三年,期间,来自不同国家的密码学家团队提交了 15 种不同的设计。竞赛结束时,只有一个提交作品,由文森特·赖曼和约翰·达曼设计的 Rijndael 被提名为获胜者。2001 年,NIST 发布了 AES 作为 FIPS(联邦信息处理标准)197 出版物的一部分。 AES,即 FIPS 标准中描述的算法,仍然是今天主要使用的密码。在本节中,我将解释 AES 的工作原理。
4.2.1 AES 提供了多少安全性?
AES 提供了三个不同版本:AES-128 使用 128 位(16 字节)密钥,AES-192 使用 192 位(24 字节)密钥,AES-256 使用 256 位(32 字节)密钥。密钥的长度决定了安全级别—越大越强。尽管如此,大多数应用都使用 AES-128,因为它提供足够的安全性(128 位安全性)。
术语 位安全性 常用来指示密码算法的安全性。例如,AES-128 指定我们已知的最佳攻击需要大约 2¹²⁸ 次操作。这个数字是巨大的,它是大多数应用所追求的安全级别。
位安全性是一个上限
128 位密钥提供 128 位安全性的事实是特定于 AES 的;这不是一个黄金法则。在某些其他算法中使用的 128 位密钥理论上可能提供的安全性不到 128 位。虽然 128 位密钥可以提供不到 128 位的安全性,但永远不会提供更多(总是有暴力破解攻击)。尝试所有可能的密钥最多需要 2¹²⁸ 次操作,将安全性至少降低到 128 位。
2¹²⁸ 有多大?注意两个 2 的幂之间的数量加倍。例如,2³ 是 2² 的两倍。如果说 2¹⁰⁰ 次操作几乎是不可能实现的,想象一下达到其两倍(2¹⁰¹)。要达到 2¹²⁸,你需要将你的初始数量加倍 128 次!简单来说,2¹²⁸ 是 340 个无法想象的无穷大。这个数字是相当巨大的,但你可以假设我们在实践中永远不可能达到这样的数字。我们也没有考虑到任何大规模复杂攻击所需的空间量,实际上同样是巨大的。
可预见的是,AES-128 将在很长一段时间内保持安全。除非密码分析方面的进展发现尚未发现的漏洞,这会减少攻击算法所需的操作数。
4.2.2 AES 的接口
查看 AES 加密的接口,我们可以看到以下内容:
-
正如前面讨论过的,该算法接受可变长度的密钥。
-
它还需要准确的 128 位纯文本。
-
它输出准确的 128 位密文。
因为 AES 加密了固定大小的纯文本,我们称其为 分组密码。后面你将在本章中看到,一些其他密码可以加密任意长度的纯文本。
解密操作恰好与此相反:它使用相同的密钥,一个 128 位密文,并返回原始的 128 位纯文本。实际上,解密是加密的逆过程。这是因为加密和解密操作是 确定性 的;无论你调用它们多少次,它们都会产生相同的结果。
从技术上讲,具有密钥的分组密码是一种置换:它将所有可能的明文映射到所有可能的密文(请参见图 4.2 中的示例)。更改密钥会更改该映射。置换也是可逆的。从密文,您可以得到回到其相应明文的映射(否则,解密将无法工作)。

图 4.2 具有密钥的密码可以被视为一种置换:它将所有可能的明文映射到所有可能的密文。
当然,我们没有空间列出所有可能的明文及其相关的密文。对于 128 位分组密码,这将是 2¹²⁸ 个映射。相反,我们设计像 AES 这样的结构,它们的行为类似于置换,并由密钥随机化。我们说它们是伪随机置换(PRPs)。
4.2.3 AES 的内部结构
让我们深入了解 AES 的内部。请注意,在加密过程中,AES 将明文的状态视为一个 4×4 字节矩阵(正如您在图 4.3 中所看到的)。

图 4.3 当进入 AES 算法时,16 字节的明文被转换为一个 4×4 矩阵。然后将对此状态进行加密,最终将其转换为 16 字节的密文。
实际上这并不重要,但这就是 AES 的定义方式。在幕后,AES 的工作方式类似于许多类似的对称密码原语,称为分组密码,它们是加密固定大小的块的密码。AES 还有一个轮函数,它会多次迭代,从原始输入(明文)开始。我在图 4.4 中对此进行了说明。

图 4.4 AES 通过对状态迭代一个轮函数来对其进行加密。轮函数接受多个参数,包括一个秘密密钥。(这些参数在图表中被省略以简化。)
每次调用轮函数都会进一步转换状态,最终产生密文。每个轮使用一个不同的轮密钥,它是从主对称密钥派生的(在所谓的密钥调度期间)。这允许对对称密钥位的细微更改产生完全不同的加密(这被称为扩散原理)。
轮函数由多个操作组成,这些操作混合和转换状态的字节。AES 的轮函数特别使用了四种不同的子函数。虽然我们会避免详细解释子函数的工作原理(您可以在任何关于 AES 的书籍中找到这些信息),但它们被命名为SubBytes、ShiftRows、MixColumns和AddRoundKey。前三者是容易可逆的(您可以从操作的输出中找到输入),但最后一个不是。它执行轮密钥和状态的异或(XOR)操作,因此需要轮密钥的知识才能反转。我在图 4.5 中说明了轮函数的内部。

图 4.5 AES 的典型轮次。(第一轮和最后一轮省略了一些操作。)四种不同的函数转换状态。每个函数都是可逆的,否则解密就不起作用。圆圈内的加法符号(⊕)是 XOR 操作的符号。
在 AES 中,轮函数的迭代次数,通常在减少的轮次上是实用的,被选择用来阻止密码分析。例如,在 AES-128 的三轮变种上存在非常有效的 总破解(恢复密钥的攻击)。通过多次迭代,密码将明文转换为看起来与原始明文完全不同的东西。明文中最微小的变化也会返回完全不同的密文。这个原则被称为 雪崩效应。
注意 现实世界中的加密算法通常通过它们提供的安全性、大小和速度进行比较。我们已经讨论了 AES 的安全性和大小;它的安全性取决于密钥大小,并且可以一次加密 128 位的数据块。就速度而言,许多 CPU 厂商已经在硬件中实现了 AES。例如,AES 新指令(AES-NI)是一组可在英特尔和 AMD CPU 中使用的指令,可用于有效地实现 AES 的加密和解密。这些特殊指令使 AES 在实践中变得极快。
你可能仍然有一个问题,那就是如何用 AES 加密超过或少于 128 位的内容?我下面会回答这个问题。
4.3 加密企鹅和 CBC 操作模式
现在我们已经介绍了 AES 分组密码并解释了它的内部工作原理,让我们看看如何在实践中使用它。分组密码的问题在于它只能单独加密一个块。要加密不是完全 128 位的内容,我们必须使用 填充 以及 操作模式。所以让我们看看这两个概念是什么。
想象一下,你想加密一条长消息。天真地,你可以将消息分成 16 字节的块(AES 的块大小)。然后,如果明文的最后一个块小于 16 字节,你可以在末尾添加一些字节,直到明文变成 16 字节长。这就是填充的目的!
有几种方式可以指定如何选择这些 填充字节,但填充的最重要方面是它必须是可逆的。一旦我们解密了密文,我们应该能够去除填充以检索原始的未填充消息。例如,简单地添加随机字节是行不通的,因为你无法辨别随机字节是否是原始消息的一部分。
最流行的填充机制通常被称为PKCS#7 填充,它首次出现在 RSA(一家公司)于 1990 年代末发布的 PKCS#7 标准中。PKCS#7 填充规定一条规则:每个填充字节的值必须设置为所需填充的长度。如果明文已经是 16 字节了怎么办?那么我们添加一个完整块的填充,设置为值 16。我在图 4.6 中用图示说明了这一点。要移除填充,你可以轻松地检查明文的最后一个字节的值,并将其解释为要移除的填充长度。

图 4.6 如果明文不是块大小的倍数,则填充所需长度以达到块大小的倍数。在图中,明文为 8 字节,因此我们使用 8 个字节(包含值 8)来填充明文,使其达到 AES 所需的 16 字节。
现在,有一个大问题我需要谈论。到目前为止,为了加密一条长消息,你只需将其分成 16 字节的块(也许你会填充最后一个块)。这种天真的方式被称为电子密码本(ECB)操作模式。正如你所学到的,加密是确定性的,因此对相同的明文块进行两次加密会导致相同的密文。这意味着通过单独加密每个块,生成的密文可能会有重复的模式。
这可能看起来没问题,但允许这些重复会导致许多问题。最明显的问题是它们泄露了有关明文的信息。其中最著名的例子是图 4.7 中的ECB 企鹅。

图 4.7 著名的 ECB 企鹅是使用电子密码本(ECB)操作模式加密的企鹅图像。由于 ECB 不隐藏重复模式,仅仅通过查看密文就可以猜出最初加密的内容。(图片来源于维基百科。)
为了安全地加密超过 128 位的明文,存在更好的操作模式可以“随机化”加密。对于 AES 来说,最流行的操作模式之一是密码块链接(CBC)。CBC 适用于任何确定性块密码(不仅仅是 AES),通过使用称为初始化向量(IV)的附加值来随机化加密。因此,IV 的长度为块大小(AES 为 16 字节)并且必须是随机且不可预测的。
要使用 CBC 操作模式加密,首先生成一个 16 字节的随机 IV(第八章告诉你如何做到这一点),然后在加密之前将生成的 IV 与明文的前 16 字节进行异或。这有效地随机化了加密。实际上,如果相同的明文使用不同的 IV 加密两次,操作模式会生成两个不同的密文。
如果有更多明文需要加密,使用前一个密文(就像我们之前使用 IV 一样)与下一个明文块进行异或运算,然后再加密。这样也会使下一个加密块变得随机。记住,加密的内容是不可预测的,应该和我们用来创建真正 IV 的随机性一样好。图 4.8 说明了 CBC 加密。

图 4.8 使用 AES 的 CBC 模式。为了加密,我们使用一个随机的初始化向量(IV),以及填充的明文(分成多个 16 字节的块)。
要使用 CBC 模式进行解密,需要反向操作。由于需要 IV,因此必须将其明文传输,与密文一起。由于 IV 应该是随机的,因此观察其值不会泄露任何信息。我在图 4.9 中说明了 CBC 解密。

图 4.9 使用 AES 的 CBC 模式。为了解密,需要相关的初始化向量(IV)。
附加参数如 IV 在密码学中很常见。然而,这些参数通常被理解不清楚,是漏洞的主要来源。在 CBC 模式下,IV 需要是唯一的(不能重复)以及不可预测的(真的需要是随机的)。这些要求可能由于多种原因而失败。因为开发人员经常对 IV 感到困惑,一些密码库已经删除了在使用 CBC 加密时指定 IV 的可能性,并自动生成一个随机的 IV。
警告 当 IV 重复或可预测时,加密再次变得确定性,并且可能出现许多巧妙的攻击。这就是著名的 BEAST 攻击(针对 TLS 协议的浏览器利用)在 TLS 协议上的情况。还要注意,其他算法可能对 IV 有不同的要求。这就是阅读手册总是很重要的原因。危险的细节隐藏在小字里。
请注意,仅仅使用一种操作模式和填充还不足以使密码可用。在下一节中,您将看到原因。
4.4 缺乏真实性,因此 AES-CBC-HMAC
到目前为止,我们未能解决一个根本性的缺陷:在 CBC 模式下,密文以及 IV 仍然可以被攻击者修改。实际上,没有完整性机制来防止这种情况!密文或 IV 的更改可能导致解密时出现意外的变化。例如,在 AES-CBC(使用 CBC 模式的 AES),攻击者可以通过翻转 IV 和密文中的特定位来翻转明文的特定位。我在图 4.10 中说明了这种攻击。

图 4.10 拦截 AES-CBC 密文的攻击者可以执行以下操作:(1)因为 IV 是公开的,所以将 IV 的位(例如从 1 到 0)进行翻转,也会(2)翻转第一个明文块的位。 (3)密文块上也可能发生位的修改。 (4)这样的更改会影响解密后的下一个明文块。 (5)请注意,篡改密文块会直接影响到该块的解密。
因此,密码或操作模式不能直接使用。它们缺乏某种完整性保护,以确保密文及其关联参数(这里是 IV)在没有触发警报的情况下无法修改。
为了防止对密文的修改,我们可以使用我们在第三章中看到的 消息认证码(MAC)。对于 AES-CBC,我们通常使用 HMAC(用于 基于哈希的 MAC )与 SHA-256 哈希函数结合使用来提供完整性。然后我们在对明文进行填充并将其加密后,将 MAC 应用于密文和 IV 上;否则,攻击者仍然可以修改 IV 而不被发现。
警告 这种构造称为 加密后进行认证。替代方案(如 认证后进行加密)有时可能会导致巧妙的攻击(如著名的 Vaudenay 填充预言攻击),因此在实践中要避免使用。
创建的认证标签可以与 IV 和密文一起传输。通常,它们全部连接在一起,如图 4.11 所示。此外,最佳实践是为 AES-CBC 和 HMAC 使用不同的密钥。

图 4.11 AES-CBC-HMAC 构造产生三个参数,通常按以下顺序连接:公共 IV、密文和认证标签。
在解密之前,需要验证标签(正如您在第三章中看到的那样,以恒定时间)。所有这些算法的组合被称为 AES-CBC-HMAC,直到我们开始采用更现代的一体化构造为止,它是最广泛使用的经过身份验证的加密模式之一。
警告 AES-CBC-HMAC 不是最开发者友好的构造。它经常实现不良,而且在使用不正确时存在一些危险的陷阱(例如,每次加密的 IV 必须 是不可预测的)。我花了几页的篇幅介绍这个算法,因为它仍然被广泛使用且仍然有效,但我建议不要使用它,而是使用我接下来介绍的更现代的构造。
4.5 一体化构造:经过身份验证的加密
加密的历史并不美好。不仅人们很少意识到没有认证的加密是危险的,而且错误地应用认证也是开发人员经常犯的系统性错误。因此,出现了大量研究,旨在标准化简化开发人员使用加密的全合一构造。在本节的其余部分,我将介绍这个新概念以及两种广泛采用的标准:AES-GCM 和 ChaCha20-Poly1305。
4.5.1 什么是带有关联数据的认证加密(AEAD)?
目前加密数据的最新方式是使用一种名为带有关联数据的认证加密(AEAD)的全合一构造。该构造与 AES-CBC-HMAC 提供的内容极为接近,因为它在保护明文的同时检测可能发生在密文上的任何修改。此外,它提供了一种验证关联数据的方法。
关联数据参数是可选的,可以为空,也可以包含与明文的加密和解密相关的元数据。这些数据不会被加密,要么是隐含的,要么与密文一起传输。此外,密文的大小比明文大,因为现在它包含了一个额外的认证标签(通常附加在密文的末尾)。
要解密密文,我们需要使用相同的隐含或传输的关联数据。结果要么是错误,表示密文在传输过程中被修改,要么是原始明文。我在图 4.12 中说明了这个新的原语。

图 4.12 Alice 和 Bob 亲自会面以达成共享密钥。然后 Alice 可以使用密钥使用 AEAD 加密算法将她的消息加密给 Bob。她可以选择验证一些关联数据(ad);例如,消息的发送者。收到密文和认证标签后,Bob 可以使用相同的密钥和关联数据解密。如果关联数据不正确或密文在传输过程中被修改,解密将失败。
让我们看看如何使用加密库来使用认证加密原语进行加密和解密。为此,我们将使用 JavaScript 编程语言和 Web Crypto API(大多数浏览器支持的官方接口,提供低级加密功能),如下列表所示。
列表 4.1 在 JavaScript 中使用 AES-GCM 进行认证加密
let config = {
name: 'AES-GCM',
length: 128 // ❶
};
let keyUsages = ['encrypt', 'decrypt'];
let key = await crypto.subtle.generateKey(config, false, keyUsages);
let iv = new Uint8Array(12);
await crypto.getRandomValues(iv); // ❷
let te = new TextEncoder();
let ad = te.encode("some associated data"); // ❸
let plaintext = te.encode("hello world");
let param = {
name: 'AES-GCM',
iv: iv,
additionalData: ad
};
let ciphertext = await crypto.subtle.encrypt(param, key, plaintext);
let result = await window.crypto.subtle.decrypt( // ❹
param, key, ciphertext); // ❹
new TextDecoder("utf-8").decode(result);
❶ 生成一个 128 位密钥,提供 128 位的安全性
❷ 随机生成一个 12 字节的 IV
❸ 使用一些关联数据来加密我们的明文。解密必须使用相同的 IV 和关联数据。
❹ 如果 IV、密文或关联数据被篡改,解密将抛出异常。
请注意,Web Crypto API 是一个低级 API,因此并不会帮助开发人员避免错误。例如,它让我们指定 IV,这是一种危险的模式。在此列表中,我使用了 AES-GCM,这是最广泛使用的 AEAD。接下来,让我们更多地了解 AES-GCM。
4.5.2 AES-GCM AEAD
最广泛使用的 AEAD 是 Galois/Counter Mode (缩写为 AES-GCM) 的 AES。它通过利用 AES 的硬件支持以及使用可以有效实现的 MAC(GMAC),被设计为高性能。
AES-GCM 自 2007 年起已被包括在 NIST 的特殊出版物(SP 800-38D)中,它是用于加密协议的主要密码,包括 TLS 协议的多个版本,该协议用于安全连接到互联网上的网站。实际上,我们可以说 AES-GCM 加密了网络。
AES-GCM 结合了 AES 中的 Counter (CTR) 模式和 GMAC 消息认证码。首先,让我们看看 CTR 模式如何与 AES 结合使用。图 4.13 展示了 AES 如何与 CTR 模式一起使用。

图 4.13 将 AES 密码与操作模式 Counter(CTR 模式)结合使用的 AES-CTR 算法。将唯一的随机数与计数器串联,并加密以产生密钥流。然后,将密钥流与实际的明文字节进行异或运算以产生加密。
AES-CTR 使用 AES 来加密一个随机数和一个数字(从 1 开始),而不是明文。这个额外的参数,“一个用于数字一次的随机数”,起到与 IV 相同的作用:它允许操作模式对 AES 加密进行随机化。然而,其要求与 CBC 模式的 IV 有些不同。一个随机数需要是唯一的,但不需要是不可预测的。一旦这个 16 字节的块被加密,结果被称为密钥流,它与实际的明文进行异或运算以产生加密结果。
非分裂密钥 (IVs) 一样,随机数(nonces)是密码学中常见的术语,在不同的密码学原语中都有出现。随机数可能有不同的要求,尽管其名称通常暗示着不应该重复使用。但通常情况下,重要的是手册上说了什么,而不是参数名称暗示了什么。事实上,AES-GCM 的随机数有时被称为 IV。
AES-CTR 中的随机数为 96 位(12 字节),大部分用于加密 16 字节的内容。剩下的 32 位(4 字节)作为计数器,从 1 开始,并在每个块加密时递增,直到达到其最大值为 2^(4×8) – 1 = 4,294,967,295. 这意味着,最多可以使用相同的随机数加密 4,294,967,295 个 128 位块(少于 69 GB)。
如果相同的随机数被使用两次,将创建相同的密钥流。通过对两个密文进行异或运算,可以取消密钥流,并且可以恢复两个明文的异或结果。这可能是毁灭性的,特别是如果你对两个明文的内容有一些了解。

图 4.14 如果 AES-CTR 的密钥流比明文长,则在与明文进行异或之前将其截断为与明文相同的长度。这使得 AES-CTR 可以在不填充的情况下工作。
图 4.14 展示了 CTR 模式的一个有趣特点:不需要填充。我们说它将分组密码(AES)转变为流密码。它按字节加密明文。
流密码
流密码是密码的另一类。它们与分组密码不同,因为我们可以直接使用它们通过与密钥流进行异或来加密密文。无需填充或操作模式,允许密文与明文长度相同。
在实践中,这两类密码之间没有太大的区别,因为通过 CTR 操作模式,分组密码很容易转换为流密码。但是,在理论上,分组密码具有优势,因为它们在构建其他类别的基元时可能会有用(类似于第二章中所见的哈希函数)。
此时也是值得注意的好时机,默认情况下,加密不会(或很差地)隐藏您正在加密的内容的长度。因此,在加密之前使用压缩可能会导致攻击,如果攻击者可以影响正在加密的部分。
AES-GCM 的第二部分是GMAC。它是从带有密钥散列(称为GHASH)构造的 MAC。从技术角度来看,GHASH 是几乎异或的通用哈希(AXU),也称为差异不可预测函数(DUF)。这样的函数的要求比哈希要弱。例如,AXU 不需要抗碰撞性。由于这个原因,GHASH 可以显着加快速度。图 4.15 说明了 GHASH 算法。

图 4.15 GHASH 使用密钥并以类似 CBC 模式的方式逐块吸收输入。它产生一个 16 字节的摘要。
使用 GHASH 进行哈希时,我们将输入分成 16 字节的块,然后以类似 CBC 模式的方式对它们进行哈希。由于此哈希需要一个密钥作为输入,因此理论上可以用作 MAC,但只能用一次(否则,算法就会破坏)—这是一次性 MAC。由于这对我们来说不理想,我们使用一种技术(由 Wegman-Carter 提出)将 GHASH 转换为多次 MAC。我在图 4.16 中进行了说明。

图 4.16 GMAC 使用带有密钥的 GHASH 对输入进行哈希,然后使用不同的密钥和 AES-CTR 进行加密,以生成认证标签。
GMAC 实际上是使用 AES-CTR(和不同的密钥)加密 GHASH 输出。再次强调,随机数必须是唯一的;否则,聪明的攻击者可以恢复 GHASH 使用的认证密钥,这将是灾难性的,并且将允许轻松伪造认证标签。
最后,AES-GCM 可以被看作是 CTR 模式和 GMAC 的交织组合,类似于我们之前讨论的加密-然后-MAC 构造。我在图 4.17 中说明了整个算法。

图 4.17 AES-GCM 通过使用对称密钥K的 AES-CTR 来加密明文,并使用 GMAC 来使用认证密钥H对相关数据和密文进行认证。
计数器从 1 开始加密,将 0 计数器留给由 GHASH 创建的加密标签。GHASH 反过来使用独立密钥H,这是使用密钥K对全零块进行加密。这样,一个密钥K就足以派生另一个密钥,不需要携带两个不同的密钥。
正如我之前所说,AES-GCM 的 12 字节 nonce 需要是唯一的,因此永远不会重复。请注意,它不需要是随机的。因此,一些人喜欢将其用作计数器,从 1 开始逐个加密。在这种情况下,必须使用一个允许用户选择 nonce 的加密库。这样可以在达到 nonce 的最大值之前加密 2^(12×8) - 1 条消息。可以说,这是一个在实践中无法达到的消息数量。
另一方面,拥有计数器意味着需要保持状态。如果一台机器在错误的时间崩溃,可能会发生 nonce 重用。因此,有时候更倾向于使用随机 nonce。实际上,一些库不允许开发人员选择 nonce,并会随机生成 nonce。这样做可以避免高概率重复,实际上不应该发生这种情况。然而,加密的消息越多,使用的 nonce 越多,发生碰撞的几率就越高。由于我们在第二章讨论的生日界限,建议在随机生成 nonce 时不要使用相同密钥加密超过 2^(92/3) ≈ 2³⁰ 条消息。
超越生日界限安全性
2³⁰ 条消息是相当大量的消息。在许多情况下可能永远不会达到这个数量,但现实世界的加密通常会推动被认为是合理的极限。一些长期存在的系统需要每秒加密许多消息,最终达到这些极限。例如,Visa 每天处理 1.5 亿笔交易。如果需要用唯一密钥加密这些交易,它将在仅一周内达到 2³⁰ 条消息的限制。在这些极端情况下,重新生成密钥(更改用于加密的密钥)可能是一个解决方案。还存在一个名为超越生日界限安全性的研究领域,旨在提高可以使用相同密钥加密的最大消息数量。
4.5.3 ChaCha20-Poly1305
我将要讨论的第二个 AEAD 是ChaCha20-Poly1305。它是两个算法的组合:ChaCha20 流密码和 Poly1305 MAC。这两个算法分别由 Daniel J. Bernstein 设计,用于在软件中快速使用,与 AES 相反,当硬件支持不可用时速度较慢。2013 年,Google 标准化了 ChaCha20-Poly1305 AEAD,以便在依赖低端处理器的 Android 手机中使用。如今,它被广泛应用于像 OpenSSH、TLS 和 Noise 这样的互联网协议中。
ChaCha20 是 Salsa20 流密码的修改版,最初由 Daniel J. Bernstein 在 2005 年左右设计。它是 ESTREAM 竞赛中的提名算法之一(www.ecrypt.eu.org/stream/)。与所有流密码一样,该算法生成一个密钥流,一个与明文长度相同的随机字节序列。然后将其与明文进行异或运算以创建密文。要解密,使用相同的算法生成相同的密钥流,将其与密文进行异或运算以还原明文。我在图 4.18 中说明了这两个流程。

图 4.18 ChaCha20 通过使用对称密钥和唯一随机数生成密钥流,然后将其与明文(或密文)进行异或运算以生成密文(或明文)。加密是保持长度不变的,因为密文和明文长度相同。
在内部,ChaCha20 通过反复调用块函数生成许多 64 字节的密钥流块来生成密钥流。
-
一个 256 位(32 字节)的类似 AES-256 的密钥
-
一个 92 位(12 字节)的类似 AES-GCM 的随机数
-
一个 32 位(4 字节)的类似 AES-GCM 的计数器
加密过程与 AES-CTR 相同。(我在图 4.19 中说明了这个流程。)
-
运行块函数,每次递增计数器,直到产生足够的密钥流
-
将密钥流截断到与明文长度相同
-
将密钥流与明文进行异或运算

图 4.19 ChaCha20 的密钥流是通过调用内部块函数生成足够的字节而创建的。一个块函数调用会创建 64 字节的随机密钥流。
由于计数器的上限,你可以使用 ChaCha20 加密与 AES-GCM 相同数量的消息(因为它是由类似的随机数参数化的)。由于这个块函数创建的输出要大得多,你可以加密的消息大小也会受到影响。你可以加密大小为 232 × 64 字节 ≈ 274 GB 的消息。如果重复使用一个随机数来加密明文,会出现与 AES-GCM 类似的问题。观察者可以通过对两个密文进行异或运算来获取两个明文的异或结果,并且还可以恢复随机数的认证密钥。这些是严重的问题,可能导致攻击者能够伪造消息!
随机数和计数器的大小
Nonce 和计数器的大小实际上并不总是相同(对于 AES-GCM 和 ChaCha20-Poly1305 都是如此),但它们是采用的标准推荐值。尽管如此,一些加密库接受不同大小的 nonce,一些应用程序增加计数器(或 nonce)的大小以允许加密更大的消息(或更多的消息)。增加一个组件的大小必然会减少另一个组件的大小。
为了防止这种情况,同时允许在单个密钥下加密大量消息,还有其他标准可用,例如 XChaCha20-Poly1305。这些标准增加了 nonce 的大小,同时保持其余部分不变,这在需要随机生成 nonce 而不是在系统中跟踪计数器的情况下很重要。
在 ChaCha20 块函数内部,形成一个状态。图 4.20 说明了这个状态。

图 4.20 ChaCha20 块函数的状态。它由 16 个字(每个字 32 字节)组成。第一行存储一个常量,第二和第三行存储 32 字节的对称密钥,接下来的一个字存储一个 4 字节的计数器,最后 3 个字存储 12 字节的 nonce。
这个状态然后通过将一个轮函数迭代 20 次(因此算法名称中有 20)转换为 64 字节的密钥流。这类似于 AES 及其轮函数的处理方式。轮函数本身每轮调用一次 Quarter Round(QR)函数,每次在内部状态的不同字上操作,具体取决于轮数是奇数还是偶数。图 4.21 展示了这个过程。

图 4.21 ChaCha20 中的一轮影响状态中包含的所有字。由于 Quarter Round (QR) 函数只接受 4 个参数,所以必须至少在不同的字上调用 4 次(在图表中显示为灰色)才能修改状态的所有 16 个字。
QR 函数接受四个不同的参数,并仅使用加法、旋转和异或操作来更新它们。我们说这是一个 ARX 流密码。这使得 ChaCha20 在软件中非常容易实现且速度快。
Poly1305 是通过 Wegman-Carter 技术创建的 MAC,与我们之前讨论的 GMAC 类似。图 4.22 说明了这个加密 MAC。

图 4.22 Poly1305 的核心函数通过每次接收一个输入块并取一个额外的累加器(最初设置为 0)和一个认证密钥 r 来吸收输入。输出被作为累加器馈送到下一个核心函数的调用。最终输出加上一个随机值 s 以成为认证标签。
在图中,r 可以看作是方案的认证密钥,就像 GMAC 的认证密钥 H 一样。而 s 通过加密结果使得 MAC 对多次使用具有安全性,因此它必须对每次使用都是唯一的。
Poly1305 核心函数将密钥与累加器(初始设置为 0)和要认证的消息混合在一起。操作是简单的乘法,对一个常数P取模。
注意 显然,我们的描述中缺少很多细节。我很少提到如何对数据进行编码或如何在执行之前对某些参数进行填充。这些都是实现特定的细节,对我们来说并不重要,因为我们正在努力理解这些事物的工作原理。
最终,我们可以使用 ChaCha20 和计数器设置为 0 来生成一个密钥流,并推导出我们需要的 16 字节r和 16 字节s值,以用于 Poly1305。我在图 4.23 中展示了结果的 AEAD 密码。

图 4.23 ChaCha20-Poly1305 通过使用 ChaCha20 加密明文并推导出 Poly1305 MAC 所需的密钥来工作。然后 Poly1305 用于认证密文以及相关数据。
首先使用普通的 ChaCha20 算法推导出 Poly1305 所需的认证密钥r和s。然后,计数器递增,并使用 ChaCha20 加密明文。之后,相关数据和密文(以及它们各自的长度)被传递给 Poly1305 以创建认证标签。
要解密,将应用完全相同的过程。ChaCha20 首先通过收到的标签验证密文和相关数据的认证。然后解密密文。
4.6 其他类型的对称加密
让我们暂停一下,回顾一下你迄今学到的对称加密算法:
-
非认证加密—带有操作模式但不带 MAC 的 AES。在实践中不安全,因为密文可能会被篡改。
-
认证加密—AES-GCM 和 ChaCha20-Poly1305 是两种最广泛采用的密码。
章节到此结束也没有问题。然而,现实世界的密码学并不总是遵循约定的标准;它还涉及到大小、速度、格式等方面的限制。因此,让我简要介绍一下当 AES-GCM 和 ChaCha20-Poly1305 不适用时可以有用的其他类型的对称加密。
4.6.1 密钥包装
基于 Nonce 的 AEAD 的问题之一是它们都需要一个 Nonce,这需要额外的空间。注意,当加密密钥时,您可能并不一定需要随机化,因为加密的内容已经是随机的,并且不会以高概率重复(或者如果它确实重复,这并不重要)。一个众所周知的密钥包装标准是 NIST 的 Special Publication 800-38F:“Recommendation for Block Cipher Modes of Operation: Methods for Key Wrapping。”这些密钥包装算法不需要额外的 Nonce 或 IV,并且根据它们加密的内容进行随机化。由于这一点,它们不必在密文旁边存储额外的 Nonce 或 IV。
4.6.2 防止滥用 Nonce 的认证加密
2006 年,菲利普·罗加韦(Phillip Rogaway)发布了一种名为合成初始化向量(SIV)的新密钥包装算法。作为提案的一部分,罗加韦指出,SIV 不仅对加密密钥有用,而且作为一种更能容忍重复 nonce 的通用 AEAD 方案。正如你在本章中学到的那样,在 AES-GCM 或 ChaCha20-Poly1305 中重复的 nonce 可能会导致灾难性后果。它不仅会揭示两个明文的异或,还允许攻击者恢复身份验证密钥并伪造消息的有效加密。
防止 nonce 误用的算法的要点是,使用相同的 nonce 加密两个明文只会显示两个明文是否相等,仅此而已。这并不理想,但显然不像泄漏身份验证密钥那样糟糕。该方案引起了很多关注,并且自那时起已被标准化为 RFC 8452:“AES-GCM-SIV:防止 nonce 误用的身份验证加密”。SIV 背后的诀窍是 AEAD 中使用的 nonce 是从明文本身生成的,这使得两个不同的明文最终被加密为相同的 nonce 的可能性极小。
4.6.3 磁盘加密
加密笔记本电脑或手机的存储有一些严重的限制:它必须快速(否则用户会注意到),而且只能在原地执行(对于大量设备来说,节省空间很重要)。由于加密不能扩展,需要一个 nonce 和身份验证标签的 AEAD 并不适合。相反,使用未经身份验证的加密。
为了防止位翻转攻击,大块(数千字节)数据的加密方式是,单个位翻转会使整个块的解密混乱。这样一来,攻击更有可能导致设备崩溃而不是达到其目标。这些构造被称为宽块密码,尽管这种方法也被称为穷人的身份验证。
Linux 系统和一些 Android 设备采用了这种方法,使用了 Adiantum,这是一种包装 ChaCha 密码的宽块构造,并于 2019 年由 Google 标准化。尽管如此,大多数设备仍然使用非理想的解决方案:微软和苹果都使用 AES-XTS,这是未经身份验证的,也不是宽块密码。
4.6.4 数据库加密
在数据库中加密数据很棘手。因为整个目的是防止数据库泄漏数据,所以用于加密和解密数据的密钥必须远离数据库服务器。因为客户端没有数据本身,所以它们在查询数据的方式上受到严重限制。
最简单的解决方案称为透明数据加密(TDE),只需加密选择的列。在某些情况下,这种方法效果很好,尽管需要小心对待用于标识正在加密的行和列的相关数据进行认证;否则,加密内容可能会被替换。但是,不能通过加密的数据进行搜索,因此查询必须使用未加密的列。
可搜索加密是旨在解决此问题的研究领域。已经提出了许多不同的方案,但似乎没有灵丹妙药。不同的方案提出了不同级别的“可搜索性”以及不同程度的安全降级。例如,盲目索引仅允许您搜索完全匹配,而保序和透露排序的加密允许您对结果进行排序。总的来说,这些解决方案的安全性需要仔细考虑,因为它们确实是一种权衡。
摘要
-
加密(或对称加密)是一种加密原语,可用于保护数据的机密性。安全性依赖于一个需要保密的对称密钥。
-
对称加密需要经过身份验证(之后我们称之为认证加密)才能确保安全,否则密文可能会被篡改。
-
认证加密可以通过使用消息认证码从对称加密算法构建。但最佳做法是使用关联数据认证加密(AEAD)算法,因为它们是一体化构造,更难被误用。
-
两个参与方可以使用认证加密来隐藏他们的通信,只要他们都知道相同的对称密钥。
-
AES-GCM 和 ChaCha20-Poly1305 是目前广泛采用的两种 AEAD(Authenticated Encryption with Associated Data)。如今大多数应用程序都使用其中一种。
-
重用一次性密码会破坏 AES-GCM 和 ChaCha20-Poly1305 的认证。诸如 AES-GCM-SIV 这样的方案是免受一次性密码误用的,而加密密钥可以避免该问题,因为一次性密码不是必需的。
-
现实世界的密码学涉及到约束,AEAD 并不总能适用于每种情况。例如,数据库或磁盘加密就需要开发新的构造。
第五章:密钥交换
本章涵盖
-
密钥交换是什么以及它们如何有用
-
Diffie-Hellman 和椭圆曲线 Diffie-Hellman 密钥交换
-
使用密钥交换时的安全考虑
现在我们进入了 非对称加密 领域(也称为 公钥加密 ) ,我们的第一个非对称加密原语:密钥交换。密钥交换正如其名称所示,是密钥的交换。例如,Alice 发送一个密钥给 Bob,Bob 发送一个密钥给 Alice。这使得两个对等方可以达成共识,产生一个共享密钥,然后可以使用认证加密算法对通信进行加密。
警告 正如我在本书引言中所暗示的,非对称加密涉及更多的数学;因此,接下来的章节对某些读者来说可能会更加困难。不要气馁!本章学到的内容将有助于理解基于相同基础的许多其他原语。
注意 对于本章,你需要已经阅读了第三章关于消息认证码和第四章关于认证加密。
5.1 什么是密钥交换?
让我们首先看一个场景,Alice 和 Bob 都想要私下交流,但之前从未互相交谈过。这将激发出在最简单的情况下密钥交换可以解锁什么。
要加密通信,Alice 可以使用你在第四章中了解到的认证加密原语。为此,Bob 需要知道相同的对称密钥,以便 Alice 可以生成一个并将其发送给 Bob。之后,他们可以简单地使用该密钥来加密他们的通信。但是,如果有人窃听他们的对话怎么办?现在敌人拥有对称密钥,可以解密 Alice 和 Bob 互相发送的所有加密内容!这就是在这种情况下使用密钥交换可以对 Alice 和 Bob(以及我们将来自己)有趣的地方。通过使用密钥交换,他们可以获得一个被动观察者无法复制的对称密钥。
密钥交换 从 Alice 和 Bob 生成一些密钥开始。为此,他们都使用一个密钥生成算法,生成一个密钥对:一个私钥(或秘密密钥)和一个公钥。然后 Alice 和 Bob 将各自的公钥发送给对方。这里的 公开 意味着敌人可以观察到,但不会产生后果。然后 Alice 使用 Bob 的公钥和她自己的私钥计算共享密钥。同样地,Bob 可以使用他的私钥和 Alice 的公钥来获得相同的共享密钥。我在图 5.1 中说明了这一点。

图 5.1 一个密钥交换提供以下接口:它采用你的对等方的公钥和你的私钥生成一个共享密钥。你的对等方可以通过使用你的公钥和他们自己的私钥获得相同的共享密钥。
从高层次了解密钥交换的工作原理后,我们现在可以回到我们的初始情景,看看这如何帮助。通过以密钥交换开始他们的通信,Alice 和 Bob 生成了一个共享的密钥,用作身份验证加密原语的密钥。因为任何观察交换的中间人(MITM)对手都无法推导出相同的共享密钥,他们将无法解密通信。我在图 5.2 中说明了这一点。

图 5.2 两个参与者之间的密钥交换使他们能够就一个密钥达成一致,而中间人(MITM)对手无法通过被动观察密钥交换来推导出相同的密钥。
请注意,这里的 MITM 是被动的;一个主动的MITM 将没有问题拦截密钥交换并冒充双方。在这种攻击中,Alice 和 Bob 实际上将与 MITM 执行密钥交换,都认为他们已经就密钥达成了一致。之所以可能是因为我们的任何一个角色都没有办法验证他们收到的公钥真正属于谁。这个密钥交换是未经身份验证的!我在图 5.3 中说明了这次攻击。

图 5.3 一个未经身份验证的密钥交换容易受到主动的中间人攻击。事实上,攻击者可以简单地冒充连接的双方并执行两次单独的密钥交换。
让我们看一个不同的情景来激发经过身份验证的密钥交换。想象一下,你想运行一个给你提供当天时间的服务。然而,你不希望这个信息被中间人攻击者修改。你最好的选择是使用你在第三章学到的消息认证码(MACs)对你的响应进行身份验证。由于 MACs 需要一个密钥,你可以简单地生成一个并手动与所有用户共享。但是,现在任何用户都拥有与其他用户一起使用的 MAC 密钥,并且可能有一天会利用它对其他人执行前面讨论的 MITM 攻击。你可以为每个用户设置不同的密钥,但这也不理想。对于想要连接到你的服务的每个新用户,你都需要手动为你的服务和用户提供一个新的 MAC 密钥。如果服务器端不需要做任何事情就好多了,是不是?
密钥交换可以在这里发挥作用!你可以做的是让你的服务生成一个密钥交换密钥对,并向服务的任何新用户提供服务的公钥。这被称为身份验证密钥交换;你的用户知道服务器的公钥,因此,主动的中间人对手无法冒充该密钥交换的一方。然而,一个恶意的人可以做的是执行他们自己的密钥交换(因为连接的客户端未经身份验证)。顺便说一句,当双方都经过身份验证时,我们称之为双向身份验证密钥交换。
这种情况非常普遍,密钥交换原语使其能够随着用户数量的增加而扩展得很好。但是,如果服务数量也增加,这种情况就不容易扩展!互联网就是一个很好的例子。我们有许多浏览器试图与许多网站进行安全通信。想象一下,如果你不得不在浏览器中硬编码你可能有一天会访问的所有网站的公钥,以及当更多的网站上线时会发生什么?
虽然密钥交换很有用,但在没有姊妹原语——数字签名的情况下,并不是所有情况下都能很好地扩展。不过这只是一个引子。在第七章中,你将了解到有关这种新的密码原语以及它如何帮助系统中的信任扩展的信息。密钥交换在实践中很少直接使用。它们通常只是更复杂协议的组成部分。话虽如此,在某些情况下它们仍然可以是有用的(例如,正如我们之前对抗被动对手时看到的)。
现在让我们看看在实践中如何使用密钥交换密码原语。libsodium 是最知名和广泛使用的 C/C++ 库之一。以下示例显示了在实践中如何使用 libsodium 来执行密钥交换。
5.1 C 语言中的密钥交换示例
unsigned char client_pk[crypto_kx_PUBLICKEYBYTES]; // ❶
unsigned char client_sk[crypto_kx_SECRETKEYBYTES]; // ❶
crypto_kx_keypair(client_pk, client_sk); // ❶
unsigned char server_pk[crypto_kx_PUBLICKEYBYTES]; // ❷
obtain(server_pk); // ❷
unsigned char decrypt_key[crypto_kx_SESSIONKEYBYTES]; // ❸
unsigned char encrypt_key[crypto_kx_SESSIONKEYBYTES]; // ❸
if (crypto_kx_client_session_keys(decrypt_key, encrypt_key,
client_pk, client_sk, server_pk) != 0) { // ❹
abort_session(); // ❺
}
❶ 生成客户端的密钥对
❷ 我们假设我们有一种获取服务器公钥的方式。
❸ libsodium 根据最佳实践派生两个对称密钥,而不是一个;每个密钥用于加密单个方向。
❹ 我们使用我们的秘密密钥和服务器的公钥进行密钥交换。
❺ 如果公钥格式错误,则函数返回错误。
libsodium 将许多细节隐藏在开发者之外,同时还公开了安全可用的接口。在这种情况下,libsodium 使用 X25519 密钥交换算法,你将在本章后面更多了解这个算法。在本章的其余部分,你将了解有关密钥交换的不同标准以及它们在幕后的工作原理。
5.2 Diffie-Hellman(DH)密钥交换
1976 年,Whitfield Diffie 和 Martin E. Hellman 发表了题为“密码学的新方向”的关键论文,介绍了 Diffie-Hellman(DH)密钥交换算法。多么响亮的标题啊!DH 是第一个发明的密钥交换算法,也是第一个公钥加密算法的正式化之一。在本节中,我将阐述该算法的数学基础,解释其工作原理,并最终讨论规定如何在加密应用中使用它的标准。
5.2.1 群论
DH 密钥交换建立在一种称为群论的数学领域之上,这是当今大多数公钥加密的基础。因此,在本章中,我将花一些时间向你介绍群论的基础知识。我将尽力提供有关这些算法如何工作的深入见解,但无论如何,这都将涉及到一些数学。
让我们从一个显而易见的问题开始:什么是群?它有两个方面:
-
一组元素
-
在这些元素上定义的特殊二元运算(例如 + 或 ×)
如果集合和运算能够满足一些属性,那么我们就有了一个群。如果我们有一个群,那么我们就可以做出神奇的事情…(稍后详述)。注意,DH 工作在一个乘法群中:一种使用乘法作为定义的二元运算的群。由于这一点,其余的解释使用乘法群作为示例。我也经常省略乘号符号(例如,我会将 a × b 写成 ab)。
我需要在这里更加具体。为了使集合及其运算成为一个群,它们需要具有以下特性。(和往常一样,我会在图 5.4 中以更加视觉化的方式来说明这些特性,以提供更多材料来理解这个新概念。)
-
封闭性——对两个元素进行操作会得到同一集合的另一个元素。例如,对于群的两个元素 a 和 b,a × b 会得到另一个群元素。
-
结合性——同时对几个元素进行操作可以按任意顺序进行。例如,对于群的三个元素 a、b 和 c,那么 a(bc) 和 (ab)c 会得到相同的群元素。
-
单位元素——与此元素进行运算不会改变另一个操作数的结果。例如,我们可以在我们的乘法群中将单位元素定义为 1。对于任何群元素 a,我们有 a × 1 = a。
-
逆元素——存在一个逆元素与所有群元素相对应。例如,对于任何群元素 a,都存在一个逆元素 a^(–1)(也写作 1/a),使得 a × a^(–1) = 1(也写作 a × 1/a = 1)。

图 5.4 群的四个属性:封闭性、结合性、单位元素和逆元素。
我可以想象我对群的解释可能有点抽象,所以让我们看看 DH 在实践中使用的群是什么。首先,DH 使用由严格正整数集合组成的群:1、2、3、4、····、p – 1,其中 p 是素数,1 是单位元素。不同的标准为 p 指定不同的数字,但直观地说,它必须是一个大素数,以确保群的安全性。
素数
素数 是只能被 1 或它本身整除的数字。前几个素数是 2、3、5、7、11 等等。素数在非对称密码学中随处可见!而且,幸运的是,我们有高效的算法来找到大素数。为了加快速度,大多数密码库会寻找伪素数(有很高概率是素数的数字)。有趣的是,此类优化在过去几次被打破过;最臭名昭著的一次发生在 2017 年,当时 ROCA 漏洞发现了超过一百万台设备为其密码应用生成了不正确的素数。
第二,DH 使用 模乘法 作为一种特殊操作。在我解释模乘法是什么之前,我需要解释什么是 模算术。直观地说,模算术是关于在达到一个称为模数的某个数后“环绕”的数字。例如,如果我们将模数设置为 5,我们说超过 5 的数字回到 1;例如,6 变成 1,7 变成 2,依此类推。(我们也将 5 记为 0,但因为它不在我们的乘法群中,所以我们不太在乎它。)
表达模算术的数学方式是取一个数与其模数的欧几里得除法的余数。让我们以数字 7 为例,并将其与 5 进行欧几里得除法得到 7 = 5 × 1 + 2。注意余数为 2。然后我们说 7 = 2 mod 5(有时写成 7 ≡ 2 (mod 5))。这个方程可以读作 7 对模 5 同余于 2。同样地
-
8 = 1 mod 7
-
54 = 2 mod 13
-
170 = 0 mod 17
-
等等
描绘这样一个概念的传统方式是用时钟。图 5.5 说明了这个概念。

图 5.5 整数模素数 5 的群可以被描绘成一个时钟,在数字 4 之后重新归零。因此 5 被表示为 0,6 被表示为 1,7 被表示为 2,8 被表示为 3,9 被表示为 4,10 被表示为 0,依此类推。
在这样一组数字上定义模乘法是相当自然的。让我们以以下乘法为例:
3 × 2 = 6
根据你之前学到的知识,你知道 6 对模 5 同余于 1,因此方程可以重写为:
3 × 2 = 1 mod 5
相当直接,是吗?请注意,前一个方程告诉我们 3 是 2 的倒数,反之亦然。我们也可以写成以下形式:
3^(–1) = 2 mod 5
当上下文清晰时,方程中的模数部分(此处为 mod 5)通常会被省略。所以如果我在这本书中有时省略了它,请不要感到惊讶。
注 事实上,当我们使用素数模下的正数时,只有零元素缺乏逆元。(确实,你能找到一个元素 b 使得 0 × b = 1 mod 5 吗?)这就是为什么我们不将零包含在群的元素中的原因。
好的,现在我们有了一个组,其中包括严格正整数 1、2、···、p – 1,p 是一个素数,以及模乘法。我们形成的组也恰好是两者:
-
交换性——操作的顺序不重要。例如,给定两个群元素 a 和 b,则 ab = ba。具有此属性的群通常被称为伽罗瓦群。
-
有限域——具有更多属性的伽罗瓦群,以及一个额外的运算(在我们的例子中,我们也可以将数字相加)。
由于最后一点,DH 定义在这种类型的群上有时被称为有限域 Diffie-Hellman(FFDH)。如果你理解什么是群(并确保在继续阅读之前理解),那么子群只是原始群中包含的一个群。也就是说,它是群元素的子集。在子群元素上操作会产生另一个子群元素,并且每个子群元素在子群中都有一个逆元素,等等。
循环子群是可以从单个生成器(或基数)生成的子群。生成器通过反复相乘来生成循环子群。例如,生成器 4 定义了由数字 1 和 4 组成的子群:
-
4 mod 5 = 4
-
4 × 4 mod 5 = 1
-
4 × 4 × 4 mod 5 = 4(我们从头开始)
-
4 × 4 × 4 × 4 mod 5 = 1
-
以此类推
注意 我们也可以将 4 × 4 × 4 写为 43。
恰好当我们的模数是素数时,我们群中的每个元素都是一个子群的生成器。这些不同的子群可以有不同的大小,我们称之为阶。我在图 5.6 中进行了说明。

图 5.6 不同的模 5 乘法群的子群。这些都包括数字 1(称为单位元素)并且具有不同的阶(元素数量)。
好了,现在你明白了
-
一个群是一组具有二元运算的数字集合,遵守一些性质(封闭性,结合性,单位元素,逆元素)。
-
DH 在 Galois 群(一个具有交换性的群)中运行,由严格正数组成,直到一个素数(不包括在内)和模乘法形成。
-
在 DH 群中,每个元素都是一个子群的生成器。
群是大量不同加密原语的中心。如果你想要理解其他加密原语的工作原理,对群论有良好的直觉是很重要的。
5.2.2 离散对数问题:Diffie-Hellman 的基础
DH 密钥交换的安全性依赖于群中的离散对数问题,这是一个被认为难以解决的问题。在本节中,我简要介绍这个问题。
想象一下,我拿一个生成器,比如说 3,然后给你一个它可以生成的随机元素,比如说 2 = 3^x mod 5,其中x对你来说是未知的。问你“x是多少?”就等同于让你找到基于 3 的 2 的离散对数。因此,在我们的群中,离散对数问题就是找出我们将生成器与自身相乘多少次才能产生给定的群元素。这是一个重要的概念!在继续之前花几分钟思考一下。
在我们的示例群中,你可以快速发现答案是 3(确实,3³ = 2 mod 5)。但是,如果我们选择一个比 5 大得多的素数,事情就变得复杂得多:变得难以解决。这就是 Diffie-Hellman 背后的秘密。现在你已经了解如何在 DH 中生成密钥对了:
-
所有参与者都必须就一个大素数 p 和一个生成器 g 达成一致。
-
每个参与者都生成一个随机数 x,这个数就成了他们的私钥。
-
每个参与者都根据 g^x mod p 推导出他们的公钥。
离散对数问题的“困难”意味着没有人应该能够从公钥中恢复出私钥。我在图 5.7 中进行了说明。

图 5.7 在 Diffie-Hellman 中选择私钥就像在生成器 g 产生的数字列表中选择索引一样。离散对数问题就是仅凭数字找到索引的问题。
尽管我们有算法来计算离散对数,但在实践中它们并不高效。另一方面,如果我给你问题的解 x,你就可以利用你手头上非常高效的算法来验证,确实我给你的是正确的解:g^x mod p。如果你感兴趣,计算模幂的最先进技术被称为“平方乘”。它通过逐位地遍历 x 来高效地计算结果。
注意就像密码学中的一切一样,仅仅通过猜测来找到解决方案是不可能的。然而,通过选择足够大的参数(在这里,一个大素数),可以将寻找解决方案的效果降低到可以忽略的几率。这意味着即使经过数百年的随机尝试,你找到解决方案的几率仍然在统计上接近于零。
很好。我们如何利用所有这些数学知识来进行 DH 密钥交换算法呢?想象一下
-
Alice 有一个私钥 a 和一个公钥 A = g^a mod p。
-
Bob 有一个私钥 b 和一个公钥 B = g^b mod p。
借助 Bob 的公钥,Alice 可以计算出共享秘密 B^a mod p。Bob 也可以利用 Alice 的公钥和他自己的私钥进行类似的计算:A^b mod p。自然地,我们可以看到这两个计算最终得到的结果是相同的:
B^a = (gb)a = g^(ab) = (ga)b = A^b mod p
这就是 DH 的魔力。从外部人士的角度来看,仅观察公钥 A 和 B 并不能以任何方式计算出密钥交换的结果 g^(ab) mod p。接下来,你将了解到现实世界的应用是如何利用这个算法以及存在的不同标准的。
计算和决策 Diffie-Hellman
顺便说一句,在理论密码学中,观察g^a mod p和g^b mod p并不会帮助你计算g^(ab) mod p的想法被称为计算 Diffie-Hellman 假设(CDH)。它经常与更强的决策 Diffie-Hellman 假设(DDH)混淆,直观地说明了在给定g^a mod p,g^b mod p和z mod p的情况下,没有人应该能够自信地猜测后者是否是两个公钥之间的密钥交换结果(g^(ab) mod p)还是组中的随机元素。这两者都是有用的理论假设,已被用于构建密码学中的许多不同算法。
5.2.3 Diffie-Hellman 标准
现在您已经了解了 DH 的工作原理,您可以理解参与者需要在一组参数上达成一致,具体来说是质数p和生成器g。在本节中,您将了解现实世界应用是如何选择这些参数以及存在的不同标准的。
首先是质数p。正如我之前所述,数字越大,效果越好。因为 DH 基于离散对数问题,其安全性与该问题已知的最佳攻击直接相关。该领域的任何进展都可能削弱算法。随着时间的推移,我们成功地对这些进展的速度(或缓慢程度)以及足够的安全性有了相当好的了解。目前已知的最佳实践是使用 2048 位的质数。
注意 一般来说,keylength.com 总结了常见加密算法的参数长度建议。结果来自研究组织或政府机构(如法国国家信息安全局(ANSSI)、美国国家标准与技术研究所(NIST)和德国联邦信息安全办公室(BSI))发布的权威文件。虽然它们并不总是一致,但它们通常会趋于类似数量级。
在过去,许多库和软件通常会生成和硬编码自己的参数。不幸的是,有时会发现它们要么是薄弱的,要么更糟,完全是破碎的。在 2016 年,有人发现了 Socat,一个流行的命令行工具,一年前已经使用了一个损坏的默认 DH 组,这就引发了一个问题,这是一个错误还是一个有意的后门。使用标准化的 DH 组可能看起来像一个更好的主意,但是 DH 是不幸的反例之一。在 Socat 问题发生几个月后,安东尼奥·桑索(Antonio Sanso)在阅读 RFC 5114 时发现,该标准也指定了损坏的 DH 组。
由于所有这些问题,更新的协议和库已经趋于要么弃用 DH 以支持椭圆曲线 Diffie-Hellman(ECDH),要么使用更好的标准 RFC 7919(www.rfc-editor.org/info/rfc7919)定义的群。因此,现在的最佳实践是使用 RFC 7919,它定义了几种不同大小和安全性的群。例如,ffdhe2048 是由 2,048 位素数模定义的群:
p = 3231700607131100730015351347782516336248805713348907517458843413926980683413621000279205636264016468
54585563579353308169288290230805734726252735547424612457410262025279165729728627063003252634282131457669
31414223654220941111348629991657478268034230553086349050635557712219187890332729569696129743856241741236
23722519734640269185579776797682301462539793305801522685873076119753243646747585546071504389684494036613
04976978128542959586595975670512838521327844685229255045682728791137200989318739591433741758378260002780
34973198552060607533234122603254684088120031105907484281003994966956119696956248629032338072839127039
以及生成器g = 2
注意 选择生成器的数字 2 是很常见的,因为计算机在使用简单的左移(<<)指令与 2 相乘时非常高效。
群大小(或order)也被指定为q = (p – 1)/2。这意味着私钥和公钥在大小上都会在 2,048 位左右。实际上,对于密钥来说,这些都是相当大的尺寸(例如,与通常为 128 位长的对称密钥相比)。您将在下一节中看到,通过定义椭圆曲线上的群,我们可以在相同的安全性下获得更小的密钥。
5.3 椭圆曲线 Diffie-Hellman(ECDH)密钥交换
结果证明,我们刚刚讨论的 DH 算法可以在不同类型的群中实现,而不仅仅是模素数的乘法群。事实证明,一个群可以由数学中研究的一种曲线——椭圆曲线构成。这个想法是由 Neal Koblitz 和 Victor S. Miller 在 1985 年独立提出的,而在 2000 年,当基于椭圆曲线的加密算法开始标准化时,这个想法得到了采纳。
应用密码学领域很快就采用了椭圆曲线密码学,因为它提供的密钥比上一代公钥密码学要小得多。与 DH 中建议的 2,048 位参数相比,椭圆曲线变体算法可以使用 256 位的参数。
5.3.1 什么是椭圆曲线?
现在让我们解释一下椭圆曲线是如何工作的。首先,首要的是要理解椭圆曲线只是曲线!这意味着它们由解方程的所有坐标x和y定义。具体来说,这个方程
y² + a[1]xy + a[3]y = x³ + a[2]x² + a[4]x + a[6]
对于一些a[1]、a[2]、a[3]、a[4]和a[6]。注意,对于今天的大多数实用曲线,这个方程可以简化为短 Weierstrass 方程:
y² = x³ + ax + b(其中 4a³ + 27b² ≠ 0)
虽然对于两种类型的曲线(称为二进制曲线和特征 3 的曲线),这种简化是不可能的,但这些曲线的使用频率很低,因此在本章的其余部分中我们将使用 Weierstrass 形式。图 5.8 显示了一个随机选取两个点的椭圆曲线示例。

图 5.8 一个由方程定义的椭圆曲线示例。
在椭圆曲线的历史上的某个时候,人们发现可以在其上构建一个群。从那时起,在这些群上实现 DH 就变得简单了。我将利用这一节来解释椭圆曲线密码学背后的直觉。
椭圆曲线上的群通常被定义为加法群。与前一节中定义的乘法群不同,这里使用的是+号。
注意 在实践中,使用加法或乘法都没有太大关系,这只是一种偏好。虽然大多数密码学使用乘法符号,但围绕椭圆曲线的文献更倾向于使用加法符号,因此,在本书中提及椭圆曲线群时,我将使用这种表示法。
这一次,我会在定义群的元素之前定义操作。我们的加法操作定义如下。图 5.9 说明了这个过程。
-
画一条穿过你想要相加的两个点的直线。这条直线在曲线上又碰到另一个点。
-
从这个新找到的点画一条垂直线。垂直线在曲线上又碰到另一个点。
-
这一点是将原始两点相加的结果。

图 5.9 通过几何方法可以在椭圆曲线的点上定义加法操作。
有两种特殊情况,这个规则不适用。我们也定义一下这两种情况:
-
*我们如何将一个点加到自身?*答案是画出该点的切线(而不是在两点之间画一条线)。
-
如果我们在第 1 步(或第 2 步)画的线不在曲线上碰到任何其他点会发生什么?嗯,这很尴尬,我们需要这种特殊情况来产生一个结果。解决方案是将结果定义为一个虚构的点(我们自己编造的)。这个新发明的点称为无穷远点(通常用大写字母O表示)。图 5.10 说明了这些特殊情况。

图 5.10 在图 5.9 的基础上构建,当将一个点与自身相加或当两个点相互抵消以得到无穷远点(O)时,也定义了在椭圆曲线上的加法。
我知道这个无穷点有些超级奇怪,但不要太担心。它实际上只是我们为了使加法运算有效而想出来的东西。哦,顺便说一下,它的行为就像一个零,它是我们的恒等元素:
O + O = O
对于曲线上的任意点P
P + O = P
一切都很好。到目前为止,我们看到要在椭圆曲线上创建一个群,我们需要
-
定义一组有效点的椭圆曲线方程。
-
在这个集合中定义加法的定义。
-
一个称为无穷点的虚拟点。
我知道这是很多需要理解的信息,但我们还缺少最后一点。椭圆曲线密码学利用之前讨论过的在有限域上定义的一种群类型。在实践中,这意味着我们的坐标是数字 1、2、···、p – 1,其中p是某个大素数。这应该听起来很熟悉!因此,当考虑椭圆曲线密码学时,您应该想象一个图形,它看起来更像图 5.11 右侧的图形。

图 5.11 椭圆曲线密码学(ECC)在实践中,主要是通过模一个大素数p的坐标椭圆曲线来指定。这意味着在密码学中使用的内容更像右图而不是左图。
就是这样!我们现在有了一个可以进行密码学运算的群,就像我们之前使用的是模一个素数的数字(排除 0)和 Diffie-Hellman 的乘法运算一样。我们如何在椭圆曲线上定义的这个群上进行 Diffie-Hellman 呢?现在让我们来看看在这个群中离散对数是如何工作的。
让我们取一个点G,并将其加上自身x次以通过我们定义的加法操作产生另一个点P。我们可以写成P = G + ··· + G(x次)或者使用一些数学上的糖来写成P = [x]G,读作x倍的G。椭圆曲线离散对数问题(ECDLP)就是要从仅知道P和G的情况下找到数字x。
注释 我们将[x]G标量乘法称为在这种群中通常称为标量的x。
5.3.2 椭圆曲线 Diffie-Hellman(ECDH)密钥交换如何工作?
现在我们在椭圆曲线上构建了一个群,我们可以在其上实例化相同的 Diffie-Hellman 密钥交换算法。要在 ECDH 中生成密钥对:
-
所有参与者都同意一个椭圆曲线方程,一个有限域(很可能是一个素数),以及一个生成元G(在椭圆曲线密码学中通常称为基点)。
-
每个参与者生成一个随机数x,这个随机数成为他们的私钥。
-
每个参与者将他们的公钥派生为[x]G。
因为椭圆曲线离散对数问题很困难,你猜对了,没有人应该能够仅仅通过查看你的公钥就恢复出你的私钥。我在图 5.12 中有例证。

图 5.12 在 ECDH 中选择一个私钥就像在由生成器(或基点)G 产生的数字列表中选择一个索引一样。椭圆曲线离散对数问题(ECDLP)是仅通过数字找到索引。
所有这些可能有点令人困惑,因为我们为 DH 群定义的操作是乘法,而对于椭圆曲线,我们现在使用加法。再次强调,这些区别完全不重要,因为它们是等价的。您可以在图 5.13 中看到比较。

图 5.13 比较了在 Diffie-Hellman 中使用的群与在椭圆曲线 Diffie-Hellman(ECDH)中使用的群。
现在你应该相信,对于密码学来说唯一重要的是我们有一个定义了操作的群,并且该群的离散对数是困难的。为了完整起见,图 5.14 展示了我们所见过的两种类型群中离散对数问题的差异。

图 5.14 在大质数模下的离散对数问题与椭圆曲线密码学(ECC)中的离散对数问题的比较。它们都与 DH 密钥交换有关,因为问题是从公钥中找到私钥。
对于理论的最后一点说明,我们在椭圆曲线之上形成的群与我们在严格正整数模素数之上形成的群不同。由于一些差异,已知的对 DH 的最强攻击(称为索引演算法或数域筛攻击)在椭圆曲线群上并不起作用。这是为什么 ECDH 的参数可以远远低于相同安全级别下 DH 的参数的主要原因。
好了,我们已经结束了理论部分。让我们回到定义 ECDH。想象一下
-
Alice 有一个私钥 a 和一个公钥 A = [a]G。
-
Bob 有一个私钥 b 和一个公钥 B = [b]G。
拥有 Bob 的公钥知识后,Alice 可以计算出共享密钥为 [a]B。Bob 可以用 Alice 的公钥和他自己的私钥进行类似的计算:[b]A。自然地,我们可以看到这两个计算最终得到相同的数字:
[a]B = [a][b]G = [ab]G = [b][a]G = [b]A
没有被动的对手应该能够仅通过观察公钥来推导出共享点。听起来很熟悉,对吧?接下来,让我们谈谈标准。
5.3.3 椭圆曲线 Diffie-Hellman 的标准
自 1985 年首次提出以来,椭圆曲线密码学一直保持着它的完整性。[…] 美国、英国、加拿大和某些其他北约国家都已经采用了某种形式的椭圆曲线密码学来保护政府之间和之内的机密信息。
—NSA(《椭圆曲线密码学的理由》,2005 年)
ECDH 的标准化过程相当混乱。许多标准化机构努力指定许多不同的曲线,然后引发了许多关于哪个曲线更安全或更高效的争论。由 Daniel J. Bernstein 领导的大量研究指出了 NIST 标准化的一些曲线可能属于 NSA 所知的更弱的曲线类别。
我不再相信这些常数。我相信美国国家安全局通过与行业的关系来操纵它们。
——Bruce Schneier(“美国国家安全局正在破解互联网上的大多数加密”,2013)
如今,大多数使用的曲线都来自一对标准,大多数应用都固定在两条曲线上:P-256 和 Curve25519。在本节的其余部分,我将介绍这些曲线。
NIST FIPS 186-4,“数字签名标准”,最初作为 2000 年签名的标准发布,其中包含一个附录,指定了 15 个用于 ECDH 的曲线。其中一条曲线,P-256,在互联网上是最广泛使用的曲线。该曲线还在 2010 年以不同名称 secp256r1 发布的 “高效密码标准” (SEC) 2,v2 中指定。P-256 使用短 Weierstrass 方程定义:
y² = x³ + ax + b mod p
其中 a = –3,而
b = 41058363725152142129326129780047268409114441015993725554835256314039467401291
和
p = 2²⁵⁶ – 2²²⁴ + 2¹⁹² + 2⁹⁶ – 1
这定义了一个素数阶的曲线:
n = 115792089210356248762697446949407573529996955224135760342422259061068512044369
这意味着曲线上确切有 n 个点(包括无穷远处的点)。基点被指定为
G = (48439561293906451759052585252797914202762949526041747995844080717082404635286, 36134250956749795798585127919587881956611106672985015071877198253568414405109)
该曲线提供了 128 位的安全性。对于使用其他提供 256 位安全性而不是 128 位安全性的密码算法(例如,具有 256 位密钥的 AES)的应用程序,同样标准中还提供了 P-521,以匹配安全级别。
我们能相信 P-256 吗?
有趣的是,FIPS 186-4 中定义的 P-256 和其他曲线据说是从一个 seed 生成的。对于 P-256,种子已知为字节字符串
0xc49d360886e704936a6678e1139d26b7819f7e90
我之前谈过“什么都没有藏在我袖子里”的概念——旨在证明算法设计没有后门的常数。不幸的是,除了指定沿曲线参数的事实之外,对 P-256 种子几乎没有解释。
RFC 7748,“用于安全的椭圆曲线”,于 2016 年发布,规定了两个曲线:Curve25519 和 Curve448。Curve25519 提供了大约 128 位的安全性,而 Curve448 则提供了大约 224 位的安全性,用于协议希望对椭圆曲线的攻击潜力进行防范。我这里只会谈论 Curve25519,它是由以下方程定义的蒙哥马利曲线:
y² = x³ + 486662 x² + x mod p,其中 p = 2²⁵⁵ – 19
Curve25519 的阶数为
n = 2²⁵² + 27742317777372353535851937790883648493
使用的基点为
G = (9, 14781619447589544791020593568409986887264606134616475288964881837755586237401)
ECDH 与 Curve25519 的结合常被称为 X25519。
5.4 小子群攻击和其他安全考虑
今天,我建议您使用 ECDH 而不是 DH,原因是密钥的大小、已知强攻击的缺乏、可用实现的质量,以及椭圆曲线的固定性和良好的标准化(与 DH 群相反,后者随处可见)。后者一点非常重要!使用 DH 可能意味着使用破损的标准(如前面提到的 RFC 5114),过于松散的协议(许多协议,如较旧版本的 TLS,不强制使用什么样的 DH 群),使用破损的自定义 DH 群的软件(前面提到的 socat 问题),等等。
如果您确实必须使用 Diffie-Hellman,请确保遵循标准。我之前提到的标准使用安全素数作为模数:形式为 p = 2q + 1 的素数,其中 q 是另一个素数。关键是,这种形式的群只有两个子群:大小为 2 的小子群(由–1 生成)和大小为 q 的大子群。(顺便说一句,这是您能得到的最好的结果;在 DH 中不存在素数阶群。)小子群的稀缺性防止了一种被称为小子群攻击的攻击(稍后详细说明)。安全素数创建了安全群,因为有两个因素:
-
模素数 p 的乘法群的阶数计算为 p – 1。
-
一个群的子群的阶数是该群的阶数的因数(这就是拉格朗日定理)。
因此,我们模素数的乘法群的阶数是 p – 1 = (2q + 1) – 1 = 2q,它的因数为 2 和 q,这意味着它的子群只能是阶数为 2 或 q 的子群。在这样的群中,小子群攻击是不可能的,因为没有足够的小子群。小子群攻击 是一种针对密钥交换的攻击,攻击者会逐渐发送几个无效的公钥来逐渐泄漏您的私钥的位,而无效的公钥是小子群的生成器。
例如,攻击者可以选择–1(大小为 2 的子群的生成器)作为公钥,并将其发送给你。通过执行你的密钥交换部分,结果的共享密钥是小子群的一个元素(–1 或 1)。这是因为你只是将小子群的生成器(攻击者的公钥)提升到你的私钥的幂。根据你对共享密钥的处理方式,攻击者可以猜测它是什么,并泄露关于你的私钥的一些信息。
对于我们恶意公钥的示例,如果你的私钥是偶数,则共享密钥将为 1,如果你的私钥是奇数,则共享密钥将为–1。因此,攻击者了解了一个信息位:你的私钥的最低有效位。许多不同大小的子群可以导致攻击者有更多机会了解你的私钥,直到整个密钥被恢复。我在图 5.15 中说明了这个问题。

图 5.15 小子群攻击影响具有许多子群的 DH 群。通过选择小子群的生成器作为公钥,攻击者可以逐渐泄露某人的私钥的位。
虽然始终验证接收到的公钥是否位于正确的子群中是一个好主意,但并不是所有的实现都这样做。2016 年,一组研究人员分析了 20 种不同的 DH 实现,并发现没有一个在验证公钥(参见 Valenta 等人的“Measuring small subgroup attacks against Diffie-Hellman”)。确保你正在使用的 DH 实现是这样做的!你可以通过将公钥提升到子群的阶,如果它是该子群的元素,那么应该返回恒等元。
另一方面,椭圆曲线允许素数阶的群。也就是说,它们没有小子群(除了由恒等元素生成的大小为 1 的子群),因此它们对小子群攻击是安全的。好吧,不要那么快……在 2000 年,Biehl、Meyer 和 Muller 发现即使在这样的素数阶椭圆曲线群中,也可能发生小子群攻击,原因是一种被称为无效曲线攻击的攻击。
无效曲线攻击背后的思想是这样的。首先,为了实现使用短 Weierstrass 方程y² = x³ + ax + b(如 NIST 的 P-256)的椭圆曲线的标量乘法,与变量b无关。这意味着攻击者可以找到具有相同方程的不同曲线,除了值b之外,其中一些曲线将具有许多小的子群。你可能知道这将导致什么:攻击者选择另一个曲线中具有小子群的点,并将其发送到目标服务器。服务器通过对给定点执行标量乘法来继续进行密钥交换,从而有效地在不同的曲线上进行密钥交换。这个技巧最终重新启用了小子群攻击,即使在素数阶曲线上也是如此。
修复这个问题的明显方法是再次验证公钥。这可以通过检查公钥不是无穷远点,并将接收到的坐标插入曲线方程中来轻松完成。看看它是否描述了定义曲线上的一个点。不幸的是,在 2015 年,Jager、Schwenk 和 Somorovsky 在“Practical Invalid Curve Attacks on TLS-ECDH”中展示了几个流行实现没有执行这些检查。如果使用 ECDH,我建议你使用 X25519 密钥交换,因为它考虑了无效曲线攻击,可用实现的质量以及设计上对抗时序攻击的抵抗力。
Curve25519 有一个警告,即它不是一个素数阶群。该曲线有两个子群:一个大小为 8 的小子群和一个用于 ECDH 的大子群。此外,原始设计没有规定验证接收到的点,并且库也没有实现这些检查。这导致在使用原语的不同类型协议中发现问题。 (其中一个我在 Matrix 消息协议中发现的问题,在第十一章中有讨论。)
不验证公钥可能会导致与 X25519 不符合预期的行为。原因在于密钥交换算法没有贡献行为:它不允许双方共同为密钥交换的最终结果做出贡献。具体来说,参与者之一可以通过发送一个小子群中的点作为公钥,强制密钥交换的结果为全零。RFC 7748 确实提到了这个问题,并建议检查生成的共享秘钥不是全零输出,但让实现者决定是否进行检查!我建议确保你的实现执行这个检查,尽管除非你以非标准方式使用 X25519,否则不太可能遇到任何问题。
由于许多协议依赖于 Curve25519,这不仅仅是密钥交换的问题。Ristretto,即将成为 RFC 的互联网草案,是一种为 Curve25519 添加额外编码层的构造,有效模拟了一个素数阶曲线(参见 tools.ietf.org/html/draft-hdevalence-cfrg-ristretto-01)。这种构造已经开始受到关注,因为它简化了其他类型的加密原语对 Curve25519 的安全假设,但又希望得到素数阶域的好处。
概要
-
未经身份验证的密钥交换允许两方达成共享秘钥,同时阻止任何被动中间人攻击者能够推导出它。
-
身份验证的密钥交换阻止主动中间人攻击者冒充连接的一方,而双向身份验证的密钥交换阻止主动中间人攻击者冒充双方。
-
通过了解对方的公钥,可以执行经过身份验证的密钥交换,但这并不总是可扩展的,而签名将解锁更复杂的场景(见第七章)。
-
迪菲-赫尔曼(DH)是第一个发明的密钥交换算法,仍然被广泛使用。
-
用于 DH 的推荐标准是 RFC 7919,其中包括几个可供选择的参数。最小选项是推荐的 2,048 位素数参数。
-
椭圆曲线迪菲-赫尔曼(ECDH)的密钥尺寸比 DH 小得多。对于 128 位的安全性,DH 需要 2,048 位的参数,而 ECDH 只需要 256 位的参数。
-
ECDH 最广泛使用的曲线是 P-256 和 Curve25519。两者都提供 128 位的安全性。对于 256 位的安全性,同一标准中还提供了 P-521 和 Curve448。
-
确保实现验证你接收到的公钥的有效性,因为无效的密钥是许多错误的源头。